> ## Documentation Index
> Fetch the complete documentation index at: https://docs.langchain.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Run an evaluation from the Playground
LangSmith allows you to run evaluations directly in the UI. The [**Playground**](/langsmith/prompt-engineering-concepts#playground) allows you to test your prompt or model configuration over a series of inputs to see how well it scores across different contexts or scenarios, without having to write any code.
Before you run an evaluation, you need to have an [existing dataset](/langsmith/evaluation-concepts#datasets). Learn how to [create a dataset from the UI](/langsmith/manage-datasets-in-application#create-a-dataset-and-add-examples).
To run evaluations from Studio instead, see [run experiments over a dataset in Studio](/langsmith/observability-studio#run-experiments-over-a-dataset). If you prefer to run experiments in code, see [run an evaluation using the SDK](/langsmith/evaluate-llm-application).
 **[Polly](/langsmith/polly)** is available in the Playground to help you optimize prompts before running evaluations.
## Create an experiment in the Playground
1. **Click Playground** in the sidebar.
2. **Add a prompt** by selecting an existing saved a prompt or creating a new one.
3. **Select a dataset** from the **Test over dataset** dropdown
* Note that the keys in the dataset input must match the input variables of the prompt. For example, in the above video the selected dataset has inputs with the key "blog", which correctly match the input variable of the prompt.
* There is a maximum of 15 input variables allowed in the Playground.
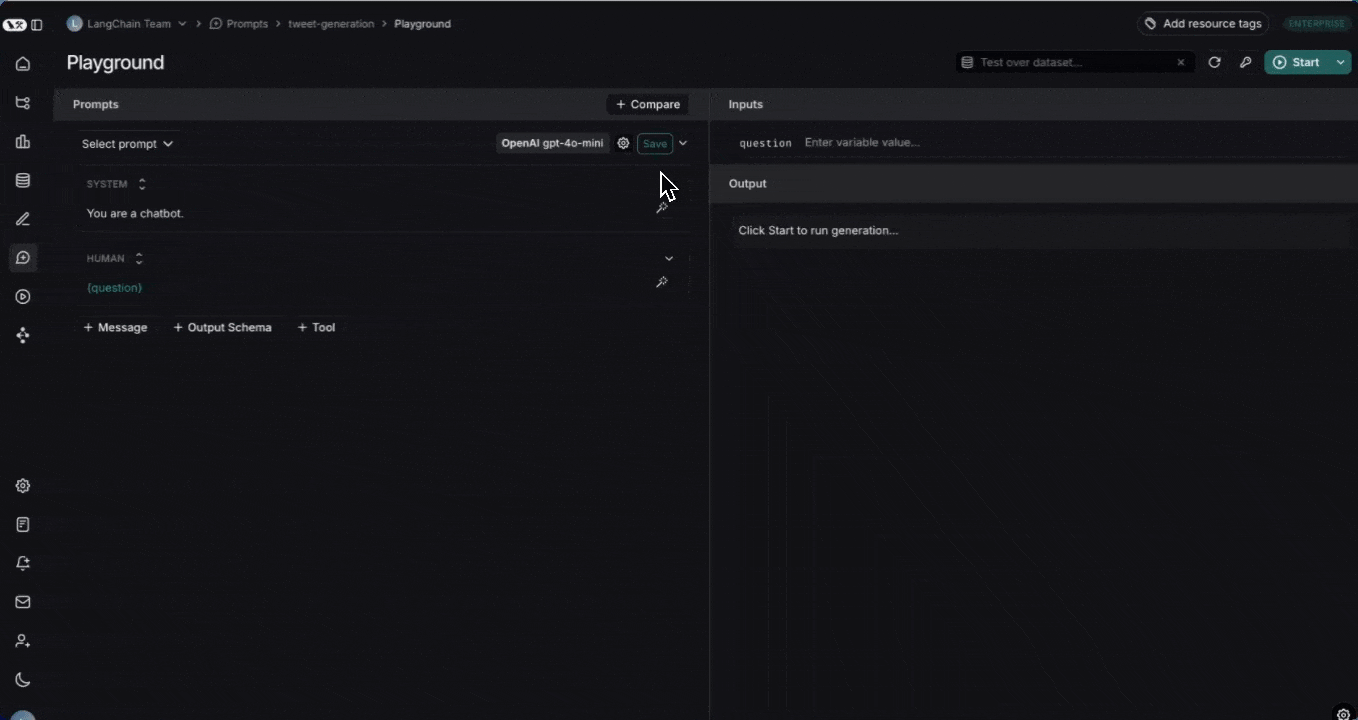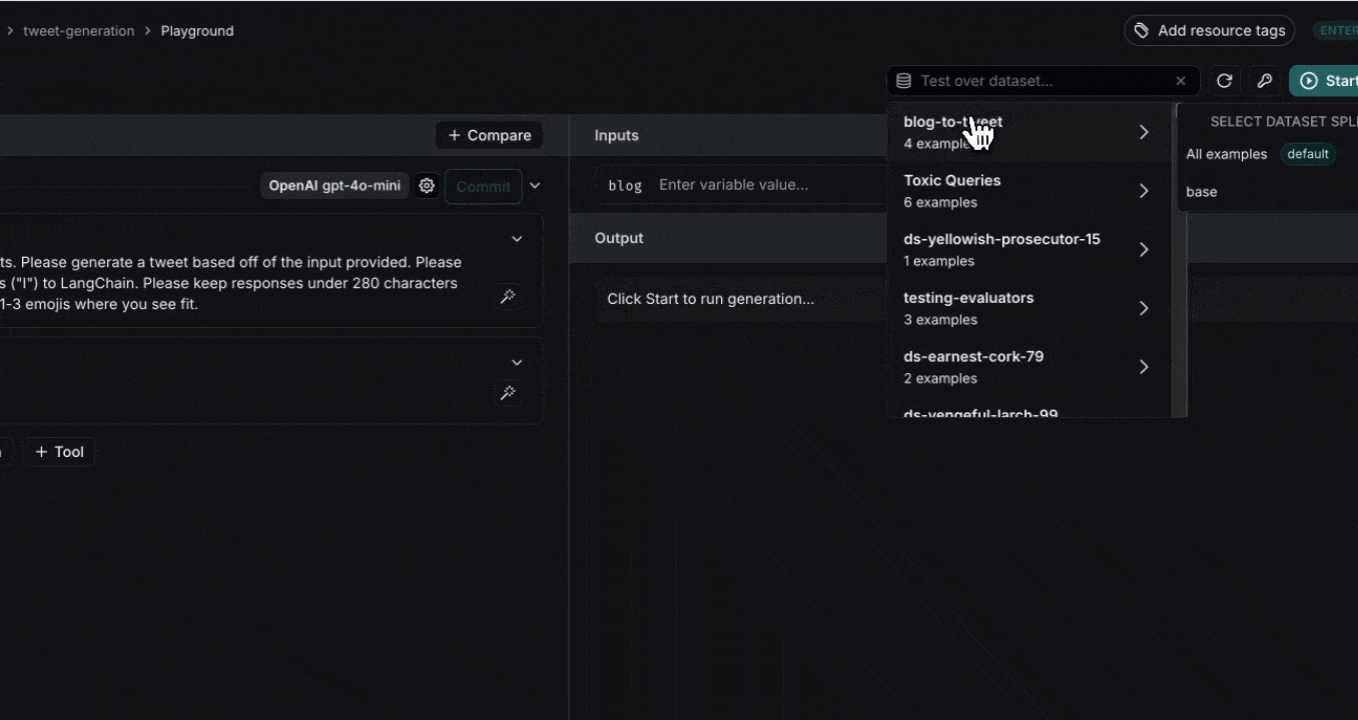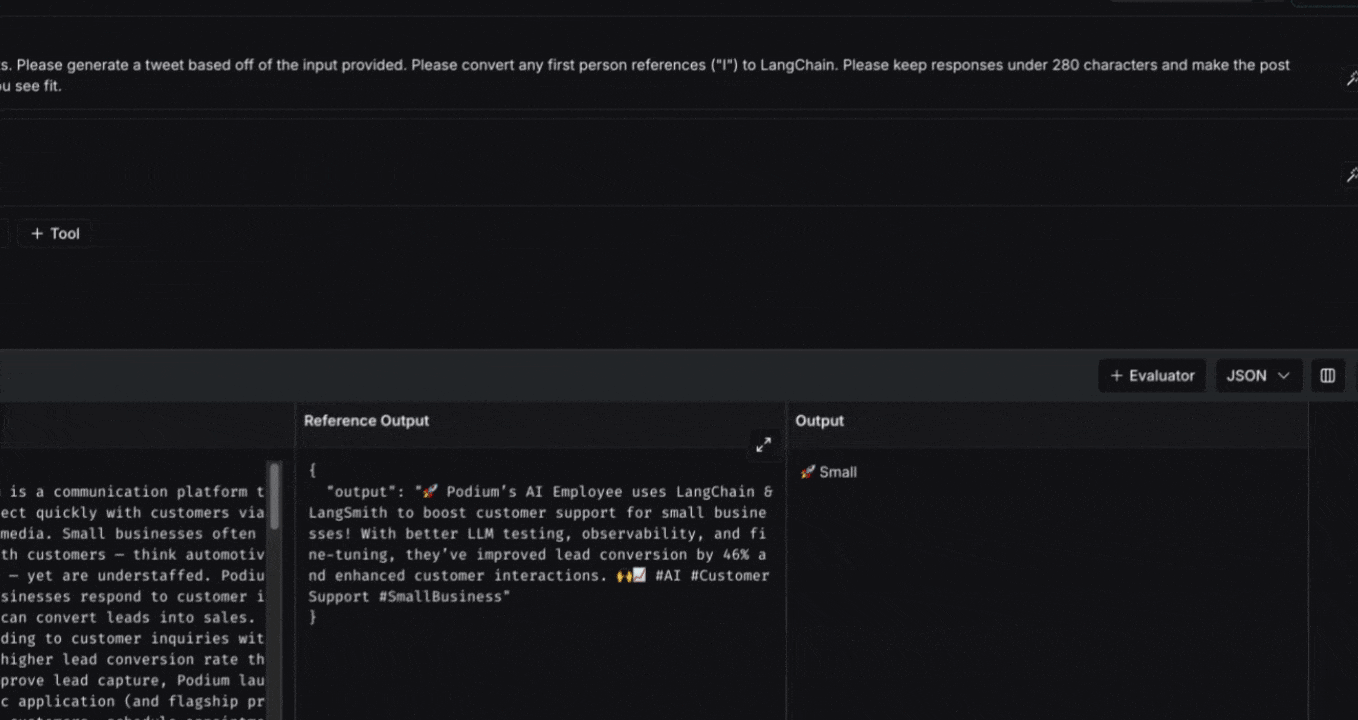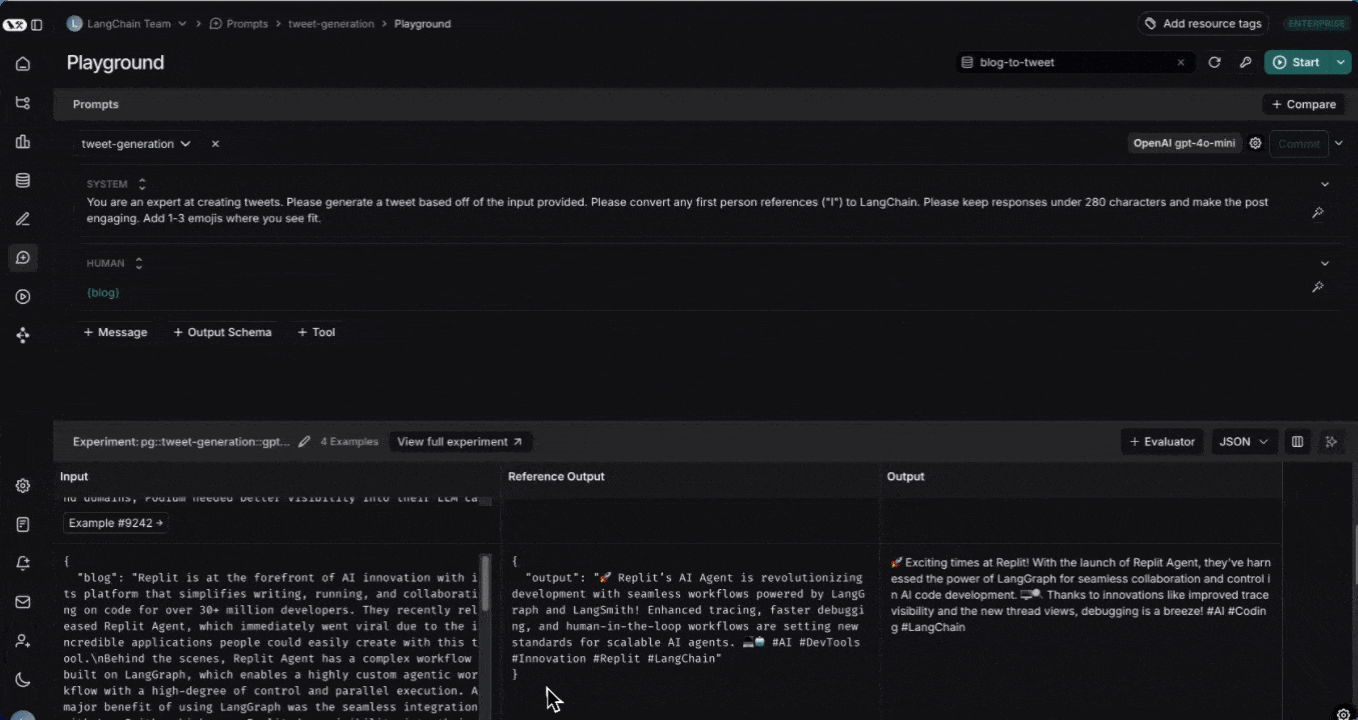
4. **Start the experiment** by clicking on the **Start** or CMD+Enter. This will run the prompt over all the examples in the dataset and create an entry for the experiment in the dataset details page. We recommend committing the prompt to the prompt hub before starting the experiment so that it can be easily referenced later when reviewing your experiment.
5. **View the full results** by clicking **View full experiment**. This will take you to the experiment details page where you can see the results of the experiment.
## Add evaluation scores to the experiment
Evaluate your experiment over specific criteria by adding evaluators. Add LLM-as-a-judge or custom code evaluators in the Playground using the **+Evaluator** button.
To learn more about adding evaluators in via UI, visit [how to define an LLM-as-a-judge evaluator](/langsmith/llm-as-judge).
***
**[Polly](/langsmith/polly)** is available in the Playground to help you optimize prompts before running evaluations.
## Create an experiment in the Playground
1. **Click Playground** in the sidebar.
2. **Add a prompt** by selecting an existing saved a prompt or creating a new one.
3. **Select a dataset** from the **Test over dataset** dropdown
* Note that the keys in the dataset input must match the input variables of the prompt. For example, in the above video the selected dataset has inputs with the key "blog", which correctly match the input variable of the prompt.
* There is a maximum of 15 input variables allowed in the Playground.
4. **Start the experiment** by clicking on the **Start** or CMD+Enter. This will run the prompt over all the examples in the dataset and create an entry for the experiment in the dataset details page. We recommend committing the prompt to the prompt hub before starting the experiment so that it can be easily referenced later when reviewing your experiment.
5. **View the full results** by clicking **View full experiment**. This will take you to the experiment details page where you can see the results of the experiment.
## Add evaluation scores to the experiment
Evaluate your experiment over specific criteria by adding evaluators. Add LLM-as-a-judge or custom code evaluators in the Playground using the **+Evaluator** button.
To learn more about adding evaluators in via UI, visit [how to define an LLM-as-a-judge evaluator](/langsmith/llm-as-judge).
***
[Connect these docs](/use-these-docs) to Claude, VSCode, and more via MCP for real-time answers.
[Edit this page on GitHub](https://github.com/langchain-ai/docs/edit/main/src/langsmith/run-evaluation-from-playground.mdx) or [file an issue](https://github.com/langchain-ai/docs/issues/new/choose).