> ## Documentation Index
> Fetch the complete documentation index at: https://docs.langchain.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Guardrails
> Implement safety checks and content filtering for your agents
Guardrails help you build safe, compliant AI applications by validating and filtering content at key points in your agent's execution. They can detect sensitive information, enforce content policies, validate outputs, and prevent unsafe behaviors before they cause problems.
Common use cases include:
* Preventing PII leakage
* Detecting and blocking prompt injection attacks
* Blocking inappropriate or harmful content
* Enforcing business rules and compliance requirements
* Validating output quality and accuracy
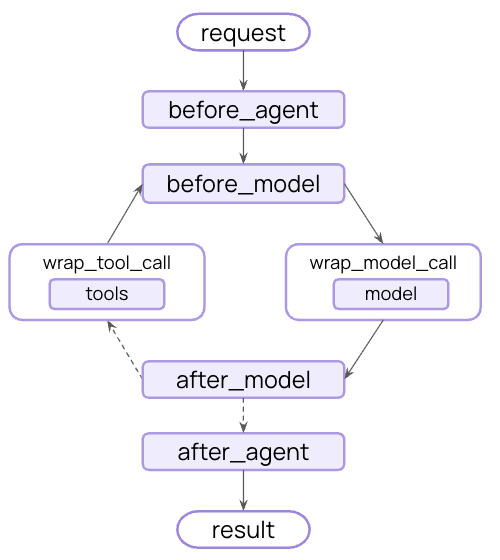
You can implement guardrails using [middleware](/oss/javascript/langchain/middleware) to intercept execution at strategic points - before the agent starts, after it completes, or around model and tool calls.
Guardrails can be implemented using two complementary approaches:
Use rule-based logic like regex patterns, keyword matching, or explicit checks. Fast, predictable, and cost-effective, but may miss nuanced violations.
Use LLMs or classifiers to evaluate content with semantic understanding. Catch subtle issues that rules miss, but are slower and more expensive.
LangChain provides both built-in guardrails (e.g., [PII detection](#pii-detection), [human-in-the-loop](#human-in-the-loop)) and a flexible middleware system for building custom guardrails using either approach.
## Built-in guardrails
### PII detection
LangChain provides built-in middleware for detecting and handling Personally Identifiable Information (PII) in conversations. This middleware can detect common PII types like emails, credit cards, IP addresses, and more.
PII detection middleware is helpful for cases such as health care and financial applications with compliance requirements, customer service agents that need to sanitize logs, and generally any application handling sensitive user data.
The PII middleware supports multiple strategies for handling detected PII:
| Strategy | Description | Example |
| -------- | --------------------------------------- | --------------------- |
| `redact` | Replace with `[REDACTED_{PII_TYPE}]` | `[REDACTED_EMAIL]` |
| `mask` | Partially obscure (e.g., last 4 digits) | `****-****-****-1234` |
| `hash` | Replace with deterministic hash | `a8f5f167...` |
| `block` | Raise exception when detected | Error thrown |
```typescript theme={"theme":{"light":"catppuccin-latte","dark":"catppuccin-mocha"}}
import { createAgent, piiRedactionMiddleware } from "langchain";
const agent = createAgent({
model: "gpt-5.4",
tools: [customerServiceTool, emailTool],
middleware: [
// Redact emails in user input before sending to model
piiRedactionMiddleware({
piiType: "email",
strategy: "redact",
applyToInput: true,
}),
// Mask credit cards in user input
piiRedactionMiddleware({
piiType: "credit_card",
strategy: "mask",
applyToInput: true,
}),
// Block API keys - raise error if detected
piiRedactionMiddleware({
piiType: "api_key",
detector: /sk-[a-zA-Z0-9]{32}/,
strategy: "block",
applyToInput: true,
}),
],
});
// When user provides PII, it will be handled according to the strategy
const result = await agent.invoke({
messages: [{
role: "user",
content: "My email is john.doe@example.com and card is 5105-1051-0510-5100"
}]
});
```
**Built-in PII types:**
* `email` - Email addresses
* `credit_card` - Credit card numbers (Luhn validated)
* `ip` - IP addresses
* `mac_address` - MAC addresses
* `url` - URLs
**Configuration options:**
| Parameter | Description | Default |
| -------------------- | ---------------------------------------------------------------------- | --------------------------- |
| `piiType` | Type of PII to detect (built-in or custom) | Required |
| `strategy` | How to handle detected PII (`"block"`, `"redact"`, `"mask"`, `"hash"`) | `"redact"` |
| `detector` | Custom detector regex pattern | `undefined` (uses built-in) |
| `applyToInput` | Check user messages before model call | `true` |
| `applyToOutput` | Check AI messages after model call | `false` |
| `applyToToolResults` | Check tool result messages after execution | `false` |
See the [middleware documentation](/oss/javascript/langchain/middleware#pii-detection) for complete details on PII detection capabilities.
### Human-in-the-loop
LangChain provides built-in middleware for requiring human approval before executing sensitive operations. This is one of the most effective guardrails for high-stakes decisions.
Human-in-the-loop middleware is helpful for cases such as financial transactions and transfers, deleting or modifying production data, sending communications to external parties, and any operation with significant business impact.
```typescript theme={"theme":{"light":"catppuccin-latte","dark":"catppuccin-mocha"}}
import { createAgent, humanInTheLoopMiddleware } from "langchain";
import { MemorySaver, Command } from "@langchain/langgraph";
const agent = createAgent({
model: "gpt-5.4",
tools: [searchTool, sendEmailTool, deleteDatabaseTool],
middleware: [
humanInTheLoopMiddleware({
interruptOn: {
// Require approval for sensitive operations
send_email: { allowAccept: true, allowEdit: true, allowRespond: true },
delete_database: { allowAccept: true, allowEdit: true, allowRespond: true },
// Auto-approve safe operations
search: false,
}
}),
],
checkpointer: new MemorySaver(),
});
// Human-in-the-loop requires a thread ID for persistence
const config = { configurable: { thread_id: "some_id" } };
// Agent will pause and wait for approval before executing sensitive tools
let result = await agent.invoke(
{ messages: [{ role: "user", content: "Send an email to the team" }] },
config
);
result = await agent.invoke(
new Command({ resume: { decisions: [{ type: "approve" }] } }),
config // Same thread ID to resume the paused conversation
);
```
See the [human-in-the-loop documentation](/oss/javascript/langchain/human-in-the-loop) for complete details on implementing approval workflows.
## Custom guardrails
For more sophisticated guardrails, you can create custom middleware that runs before or after the agent executes. This gives you full control over validation logic, content filtering, and safety checks.
### Before agent guardrails
Use "before agent" hooks to validate requests once at the start of each invocation. This is useful for session-level checks like authentication, rate limiting, or blocking inappropriate requests before any processing begins.
```typescript theme={"theme":{"light":"catppuccin-latte","dark":"catppuccin-mocha"}}
import { createMiddleware, AIMessage } from "langchain";
const contentFilterMiddleware = (bannedKeywords: string[]) => {
const keywords = bannedKeywords.map(kw => kw.toLowerCase());
return createMiddleware({
name: "ContentFilterMiddleware",
beforeAgent: {
hook: (state) => {
// Get the first user message
if (!state.messages || state.messages.length === 0) {
return;
}
const firstMessage = state.messages[0];
if (firstMessage._getType() !== "human") {
return;
}
const content = firstMessage.content.toString().toLowerCase();
// Check for banned keywords
for (const keyword of keywords) {
if (content.includes(keyword)) {
// Block execution before any processing
return {
messages: [
new AIMessage(
"I cannot process requests containing inappropriate content. Please rephrase your request."
)
],
jumpTo: "end",
};
}
}
return;
},
canJumpTo: ['end']
}
});
};
// Use the custom guardrail
import { createAgent } from "langchain";
const agent = createAgent({
model: "gpt-5.4",
tools: [searchTool, calculatorTool],
middleware: [
contentFilterMiddleware(["hack", "exploit", "malware"]),
],
});
// This request will be blocked before any processing
const result = await agent.invoke({
messages: [{ role: "user", content: "How do I hack into a database?" }]
});
```
### After agent guardrails
Use "after agent" hooks to validate final outputs once before returning to the user. This is useful for model-based safety checks, quality validation, or final compliance scans on the complete agent response.
```typescript theme={"theme":{"light":"catppuccin-latte","dark":"catppuccin-mocha"}}
import { createMiddleware, AIMessage, initChatModel } from "langchain";
const safetyGuardrailMiddleware = () => {
const safetyModel = initChatModel("gpt-5.4-mini");
return createMiddleware({
name: "SafetyGuardrailMiddleware",
afterAgent: {
hook: async (state) => {
// Get the final AI response
if (!state.messages || state.messages.length === 0) {
return;
}
const lastMessage = state.messages[state.messages.length - 1];
if (lastMessage._getType() !== "ai") {
return;
}
// Use a model to evaluate safety
const safetyPrompt = `Evaluate if this response is safe and appropriate.
Respond with only 'SAFE' or 'UNSAFE'.
Response: ${lastMessage.content.toString()}`;
const result = await safetyModel.invoke([
{ role: "user", content: safetyPrompt }
]);
if (result.content.toString().includes("UNSAFE")) {
return {
messages: [
new AIMessage(
"I cannot provide that response. Please rephrase your request."
)
],
jumpTo: "end",
};
}
return;
},
canJumpTo: ['end']
}
});
};
// Use the safety guardrail
import { createAgent } from "langchain";
const agent = createAgent({
model: "gpt-5.4",
tools: [searchTool, calculatorTool],
middleware: [safetyGuardrailMiddleware()],
});
const result = await agent.invoke({
messages: [{ role: "user", content: "How do I make explosives?" }]
});
```
### Combine multiple guardrails
You can stack multiple guardrails by adding them to the middleware array. They execute in order, allowing you to build layered protection:
```typescript theme={"theme":{"light":"catppuccin-latte","dark":"catppuccin-mocha"}}
import { createAgent, piiRedactionMiddleware, humanInTheLoopMiddleware } from "langchain";
const agent = createAgent({
model: "gpt-5.4",
tools: [searchTool, sendEmailTool],
middleware: [
// Layer 1: Deterministic input filter (before agent)
contentFilterMiddleware(["hack", "exploit"]),
// Layer 2: PII protection (before and after model)
piiRedactionMiddleware({
piiType: "email",
strategy: "redact",
applyToInput: true,
}),
piiRedactionMiddleware({
piiType: "email",
strategy: "redact",
applyToOutput: true,
}),
// Layer 3: Human approval for sensitive tools
humanInTheLoopMiddleware({
interruptOn: {
send_email: { allowAccept: true, allowEdit: true, allowRespond: true },
}
}),
// Layer 4: Model-based safety check (after agent)
safetyGuardrailMiddleware(),
],
});
```
## Additional resources
* [Middleware documentation](/oss/javascript/langchain/middleware) - Complete guide to custom middleware
* [Middleware API reference](https://reference.langchain.com/python/langchain/middleware/) - Complete guide to custom middleware
* [Human-in-the-loop](/oss/javascript/langchain/human-in-the-loop) - Add human review for sensitive operations
* [Testing agents](/oss/javascript/langchain/test/) - Strategies for testing safety mechanisms
***
[Connect these docs](/use-these-docs) to Claude, VSCode, and more via MCP for real-time answers.
[Edit this page on GitHub](https://github.com/langchain-ai/docs/edit/main/src/oss/langchain/guardrails.mdx) or [file an issue](https://github.com/langchain-ai/docs/issues/new/choose).