= async (state, runtime) => {
// Get the user id from the config
const userId = runtime.context?.user_id;
// Namespace the memory
const namespace = [userId, "memories"];
// Search based on the most recent message
const memories = await runtime.store?.search(namespace, {
query: state.messages[state.messages.length - 1].content,
limit: 3,
});
const info = memories.map((d) => d.value.memory).join("\n");
// ... Use memories in the model call
};
```
If we create a new thread, we can still access the same memories so long as the `user_id` is the same.
```typescript theme={"theme":{"light":"catppuccin-latte","dark":"catppuccin-mocha"}}
// Invoke the graph
const config = { configurable: { thread_id: "2" }, context: { userId: "1" } };
// Let's say hi again
for await (const update of await graph.stream(
{ messages: [{ role: "user", content: "hi, tell me about my memories" }] },
{ ...config, streamMode: "updates" }
)) {
console.log(update);
}
```
When we use the LangSmith, either locally (e.g., in [Studio](/langsmith/studio)) or [hosted with LangSmith](/langsmith/platform-setup), the base store is available to use by default and does not need to be specified during graph compilation. To enable semantic search, however, you **do** need to configure the indexing settings in your `langgraph.json` file. For example:
```json theme={"theme":{"light":"catppuccin-latte","dark":"catppuccin-mocha"}}
{
...
"store": {
"index": {
"embed": "openai:text-embeddings-3-small",
"dims": 1536,
"fields": ["$"]
}
}
}
```
See the [deployment guide](/langsmith/semantic-search) for more details and configuration options.
## Optimize checkpoint storage
## Checkpointer libraries
Under the hood, checkpointing is powered by checkpointer objects that conform to [`BaseCheckpointSaver`](https://reference.langchain.com/javascript/langchain-langgraph/index/BaseCheckpointSaver) interface. LangGraph provides several checkpointer implementations, all implemented via standalone, installable libraries.
* `@langchain/langgraph-checkpoint`: The base interface for checkpointer savers ([`BaseCheckpointSaver`](https://reference.langchain.com/javascript/langchain-langgraph/index/BaseCheckpointSaver)) and serialization/deserialization interface ([`SerializerProtocol`](https://reference.langchain.com/javascript/langchain-langgraph-checkpoint/SerializerProtocol)). Includes in-memory checkpointer implementation ([`MemorySaver`](https://reference.langchain.com/javascript/langchain-langgraph/index/MemorySaver)) for experimentation. LangGraph comes with `@langchain/langgraph-checkpoint` included.
* `@langchain/langgraph-checkpoint-sqlite`: An implementation of LangGraph checkpointer that uses SQLite database ([`SqliteSaver`](https://reference.langchain.com/javascript/langchain-langgraph-checkpoint-sqlite/SqliteSaver)). Ideal for experimentation and local workflows. Needs to be installed separately.
* `@langchain/langgraph-checkpoint-postgres`: An advanced checkpointer that uses Postgres database ([`PostgresSaver`](https://reference.langchain.com/javascript/langchain-langgraph-checkpoint-postgres/index/PostgresSaver)), used in LangSmith. Ideal for using in production. Needs to be installed separately.
* `@langchain/langgraph-checkpoint-mongodb`: An advanced checkpointer (`MongoDBSaver`) and long-term memory store (`MongoDBStore`) backed by MongoDB. The store supports cross-thread persistence with optional integrated vector search. Ideal for production use. Needs to be installed separately.
* `@langchain/langgraph-checkpoint-redis`: An advanced checkpointer that uses Redis database (`RedisSaver`). Ideal for using in production. Needs to be installed separately.
### Checkpointer interface
Each checkpointer conforms to the [`BaseCheckpointSaver`](https://reference.langchain.com/javascript/langchain-langgraph/index/BaseCheckpointSaver) interface and implements the following methods:
* `.put` - Store a checkpoint with its configuration and metadata.
* `.putWrites` - Store intermediate writes linked to a checkpoint (i.e. [pending writes](#pending-writes)).
* `.getTuple` - Fetch a checkpoint tuple using for a given configuration (`thread_id` and `checkpoint_id`). This is used to populate `StateSnapshot` in `graph.getState()`.
* `.list` - List checkpoints that match a given configuration and filter criteria. This is used to populate state history in `graph.getStateHistory()`
***
[Connect these docs](/use-these-docs) to Claude, VSCode, and more via MCP for real-time answers.
[Edit this page on GitHub](https://github.com/langchain-ai/docs/edit/main/src/oss/langgraph/persistence.mdx) or [file an issue](https://github.com/langchain-ai/docs/issues/new/choose).
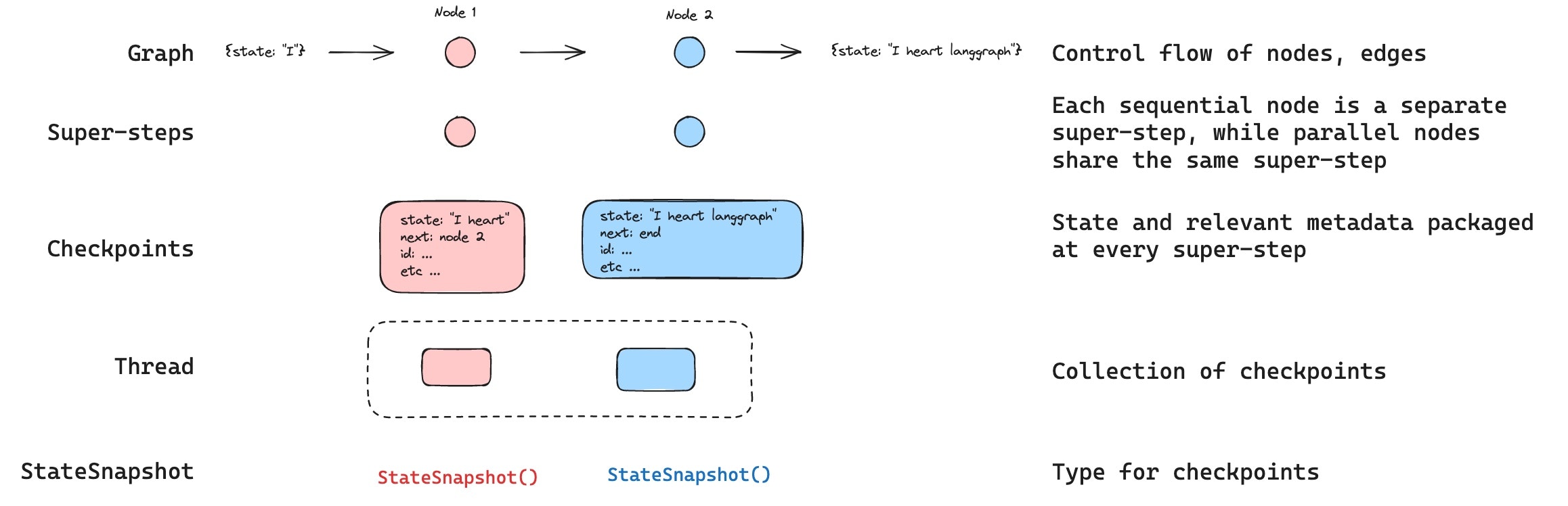
 #### Find a specific checkpoint
You can filter the state history to find checkpoints matching specific criteria:
```typescript theme={"theme":{"light":"catppuccin-latte","dark":"catppuccin-mocha"}}
const history: StateSnapshot[] = [];
for await (const state of graph.getStateHistory(config)) {
history.push(state);
}
// Find the checkpoint before a specific node executed
const beforeNodeB = history.find((s) => s.next.includes("nodeB"));
// Find a checkpoint by step number
const step2 = history.find((s) => s.metadata.step === 2);
// Find checkpoints created by updateState
const forks = history.filter((s) => s.metadata.source === "update");
// Find the checkpoint where an interrupt occurred
const interrupted = history.find(
(s) => s.tasks.length > 0 && s.tasks.some((t) => t.interrupts.length > 0)
);
```
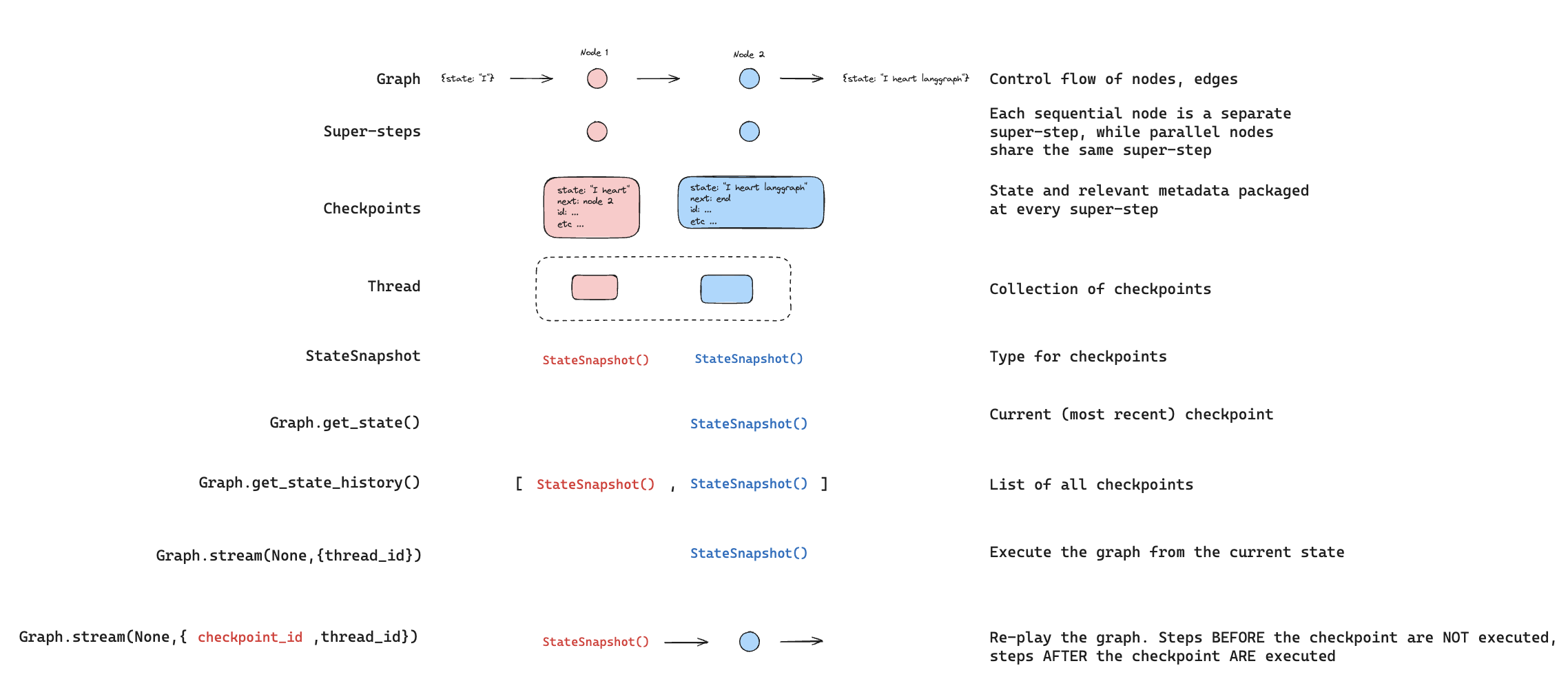
### Replay
Replay re-executes steps from a prior checkpoint. Invoke the graph with a prior `checkpoint_id` to re-run nodes after that checkpoint. Nodes before the checkpoint are skipped (their results are already saved). Nodes after the checkpoint re-execute, including any LLM calls, API requests, or [interrupts](/oss/javascript/langgraph/interrupts) — which are always re-triggered during replay.
See [Time travel](/oss/javascript/langgraph/use-time-travel) for full details and code examples on replaying past executions.
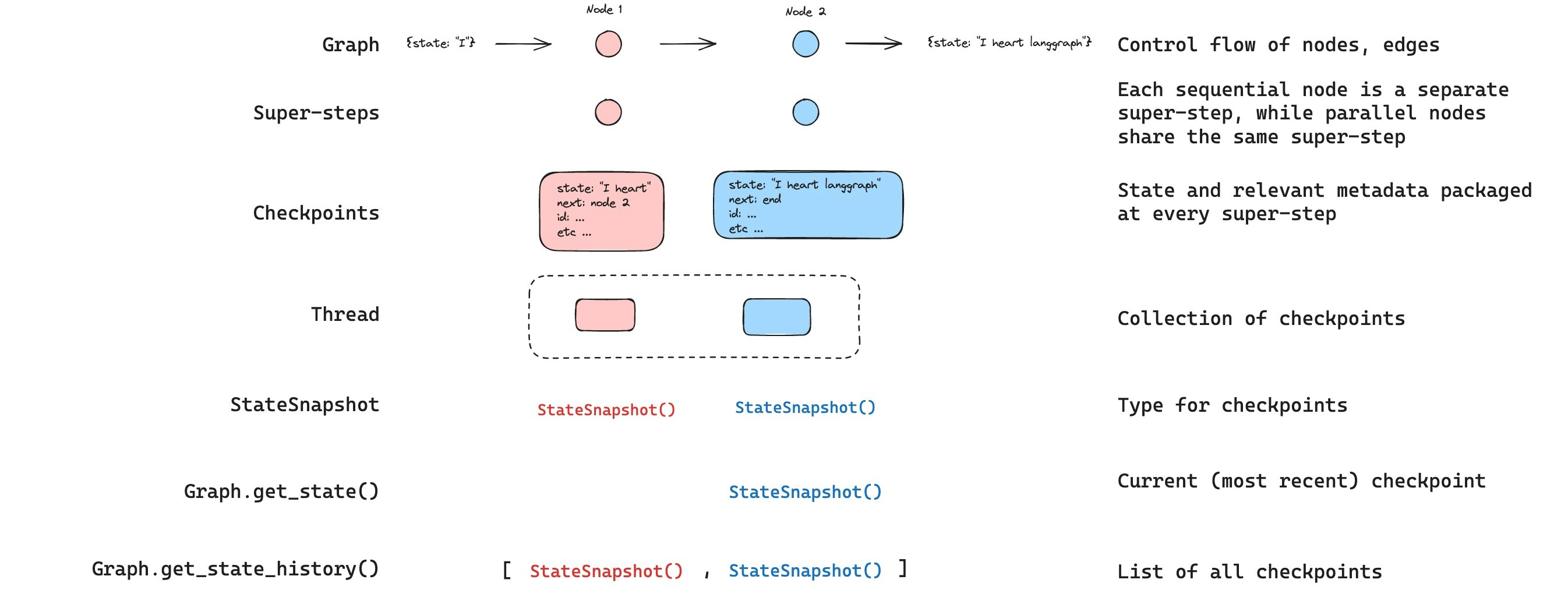
#### Find a specific checkpoint
You can filter the state history to find checkpoints matching specific criteria:
```typescript theme={"theme":{"light":"catppuccin-latte","dark":"catppuccin-mocha"}}
const history: StateSnapshot[] = [];
for await (const state of graph.getStateHistory(config)) {
history.push(state);
}
// Find the checkpoint before a specific node executed
const beforeNodeB = history.find((s) => s.next.includes("nodeB"));
// Find a checkpoint by step number
const step2 = history.find((s) => s.metadata.step === 2);
// Find checkpoints created by updateState
const forks = history.filter((s) => s.metadata.source === "update");
// Find the checkpoint where an interrupt occurred
const interrupted = history.find(
(s) => s.tasks.length > 0 && s.tasks.some((t) => t.interrupts.length > 0)
);
```
### Replay
Replay re-executes steps from a prior checkpoint. Invoke the graph with a prior `checkpoint_id` to re-run nodes after that checkpoint. Nodes before the checkpoint are skipped (their results are already saved). Nodes after the checkpoint re-execute, including any LLM calls, API requests, or [interrupts](/oss/javascript/langgraph/interrupts) — which are always re-triggered during replay.
See [Time travel](/oss/javascript/langgraph/use-time-travel) for full details and code examples on replaying past executions.
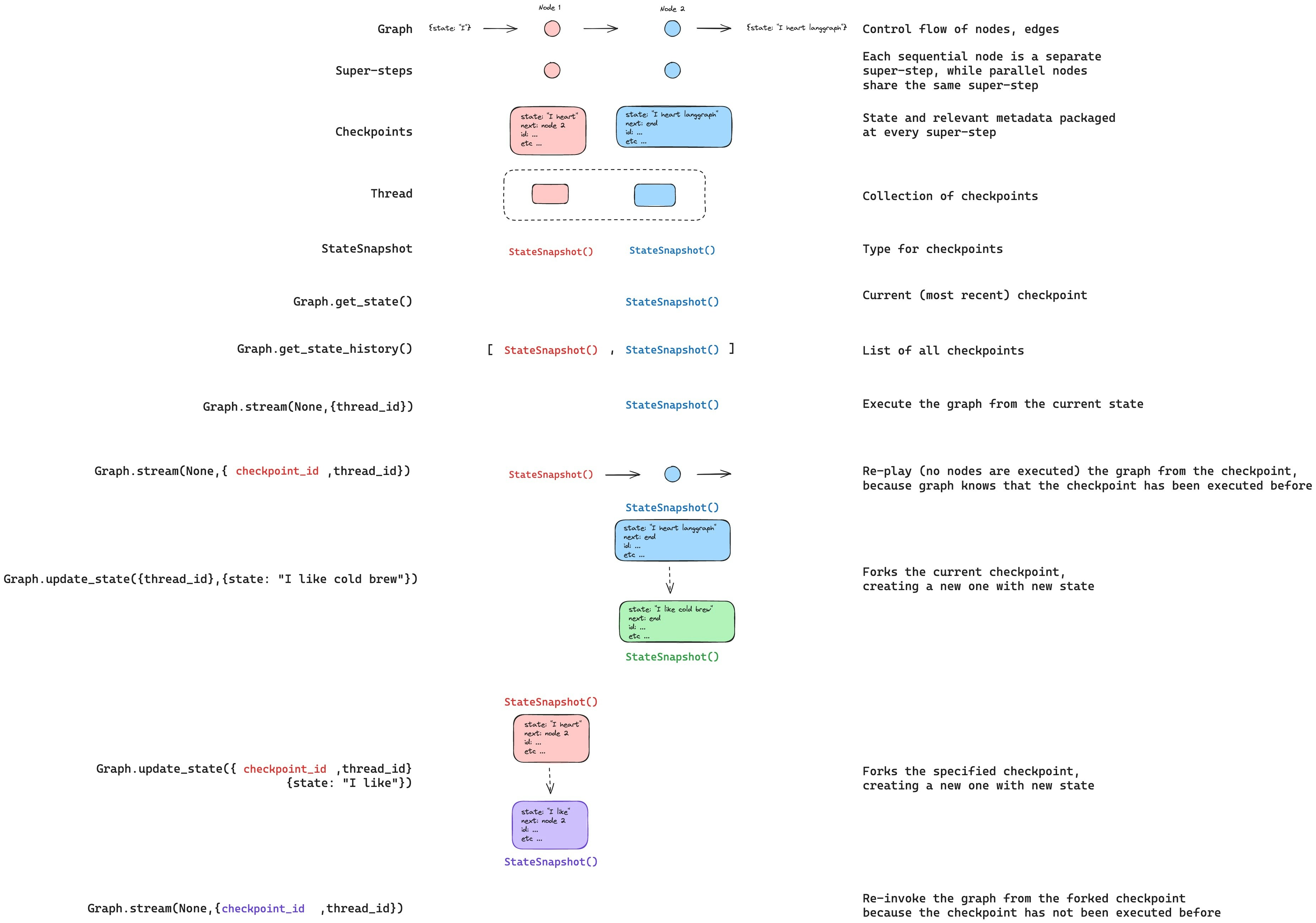
 ### Update state
You can edit the graph state using `graph.updateState()`. This creates a new checkpoint with the updated values — it does not modify the original checkpoint. The update is treated the same as a node update: values are passed through [reducer](/oss/javascript/langgraph/graph-api#reducers) functions when defined, so channels with reducers *accumulate* values rather than overwrite them.
You can optionally specify `asNode` to control which node the update is treated as coming from, which affects which node executes next. See [Time travel: `asNode`](/oss/javascript/langgraph/use-time-travel#from-a-specific-node) for details.
### Update state
You can edit the graph state using `graph.updateState()`. This creates a new checkpoint with the updated values — it does not modify the original checkpoint. The update is treated the same as a node update: values are passed through [reducer](/oss/javascript/langgraph/graph-api#reducers) functions when defined, so channels with reducers *accumulate* values rather than overwrite them.
You can optionally specify `asNode` to control which node the update is treated as coming from, which affects which node executes next. See [Time travel: `asNode`](/oss/javascript/langgraph/use-time-travel#from-a-specific-node) for details.
 ## Memory store
## Memory store
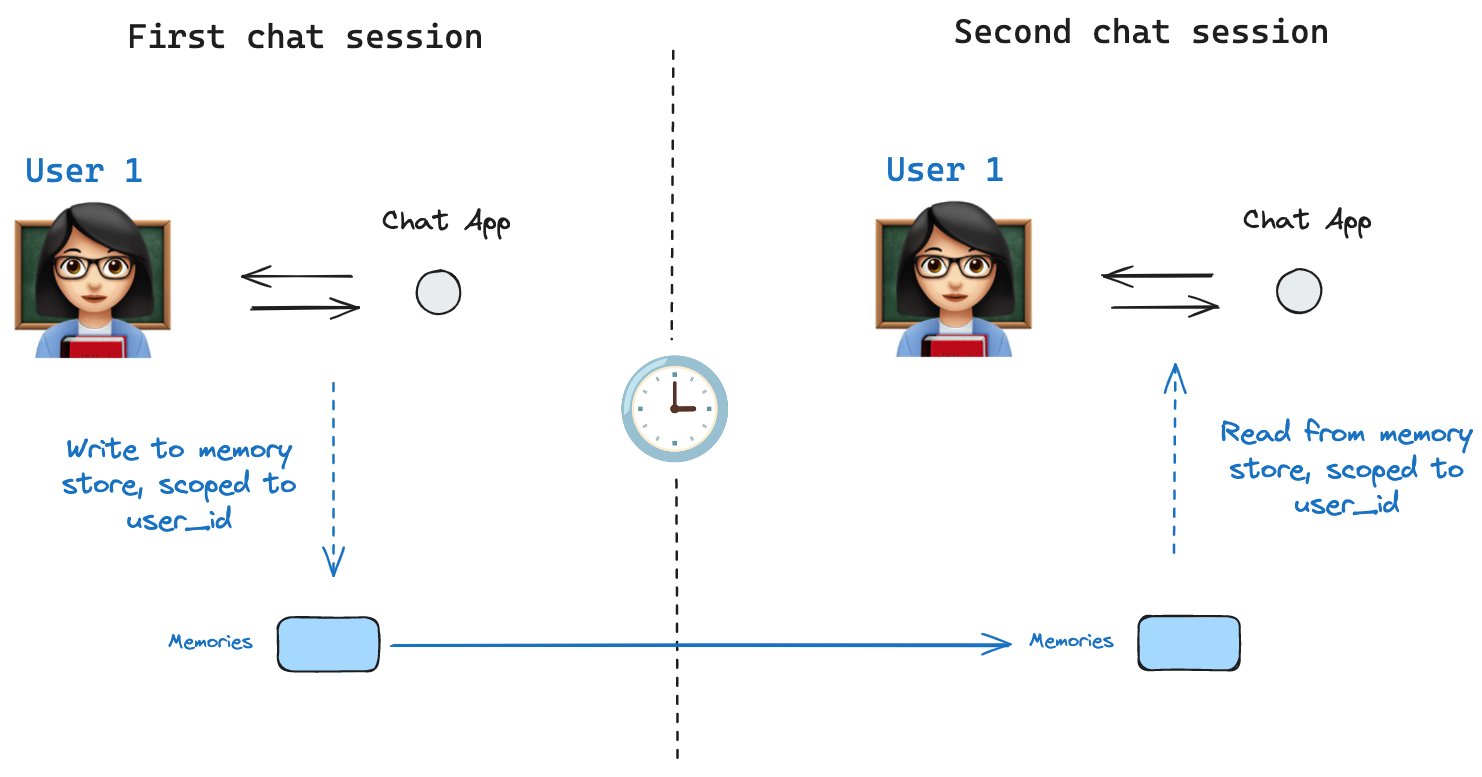 A [state schema](/oss/javascript/langgraph/graph-api#schema) specifies a set of keys that are populated as a graph is executed. As discussed above, state can be written by a checkpointer to a thread at each graph step, enabling state persistence.
What if we want to retain some information *across threads*? Consider the case of a chatbot where we want to retain specific information about the user across *all* chat conversations (e.g., threads) with that user!
With checkpointers alone, we cannot share information across threads. This motivates the need for the [`Store`](https://reference.langchain.com/python/langgraph/store/) interface. As an illustration, we can define an `InMemoryStore` to store information about a user across threads. We simply compile our graph with a checkpointer, as before, and pass the store.
A [state schema](/oss/javascript/langgraph/graph-api#schema) specifies a set of keys that are populated as a graph is executed. As discussed above, state can be written by a checkpointer to a thread at each graph step, enabling state persistence.
What if we want to retain some information *across threads*? Consider the case of a chatbot where we want to retain specific information about the user across *all* chat conversations (e.g., threads) with that user!
With checkpointers alone, we cannot share information across threads. This motivates the need for the [`Store`](https://reference.langchain.com/python/langgraph/store/) interface. As an illustration, we can define an `InMemoryStore` to store information about a user across threads. We simply compile our graph with a checkpointer, as before, and pass the store.