

Engine for self-hosted is coming soon!
- Code (optional): your agent’s source, which Engine reads to diagnose issues and propose fixes.
- Traces: runtime data from your agents, which can include user messages, tool outputs, and PII.
- Model: the LLM calls Engine makes to run diagnosis, generate fixes, and write evaluators.
How inference works
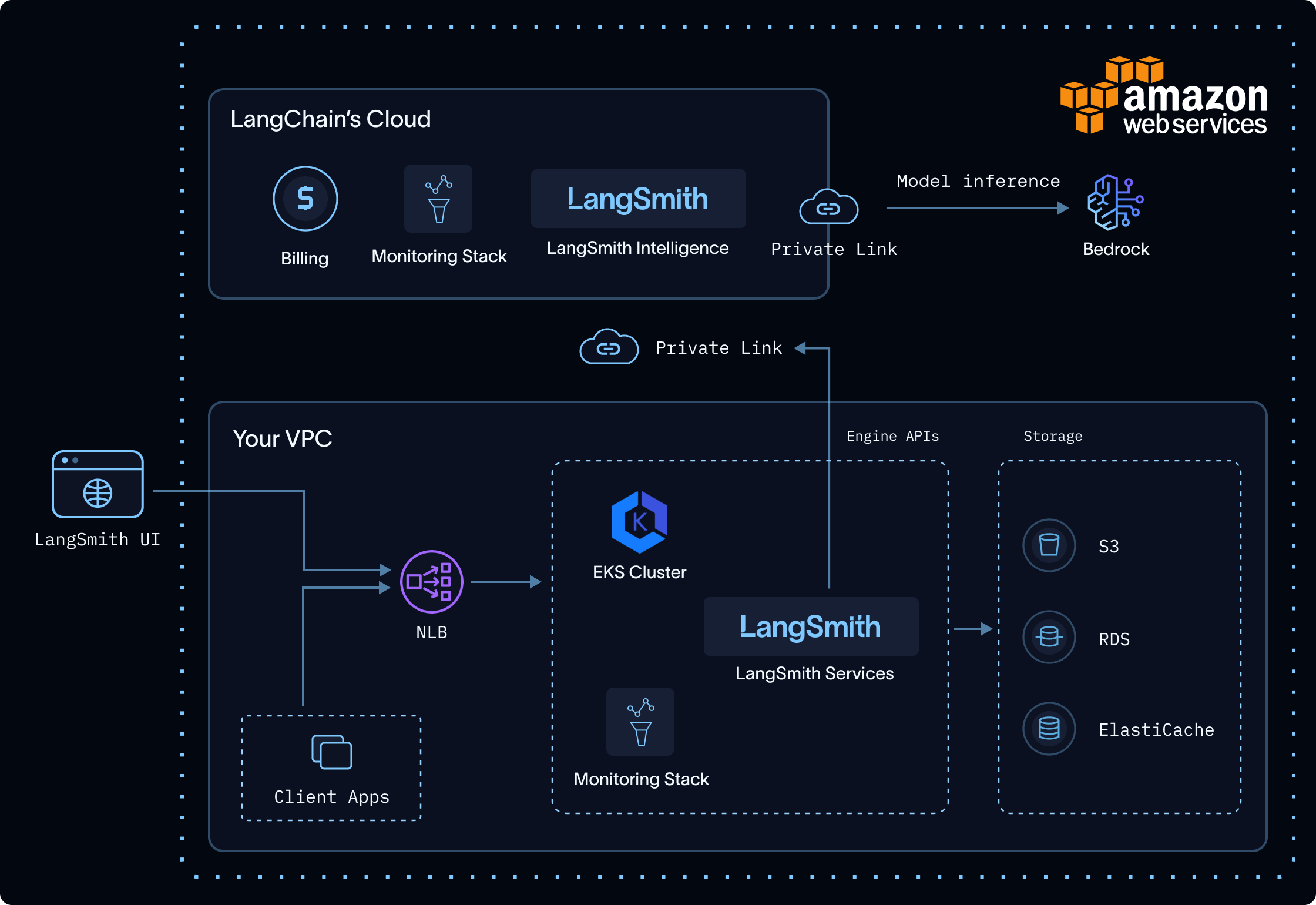
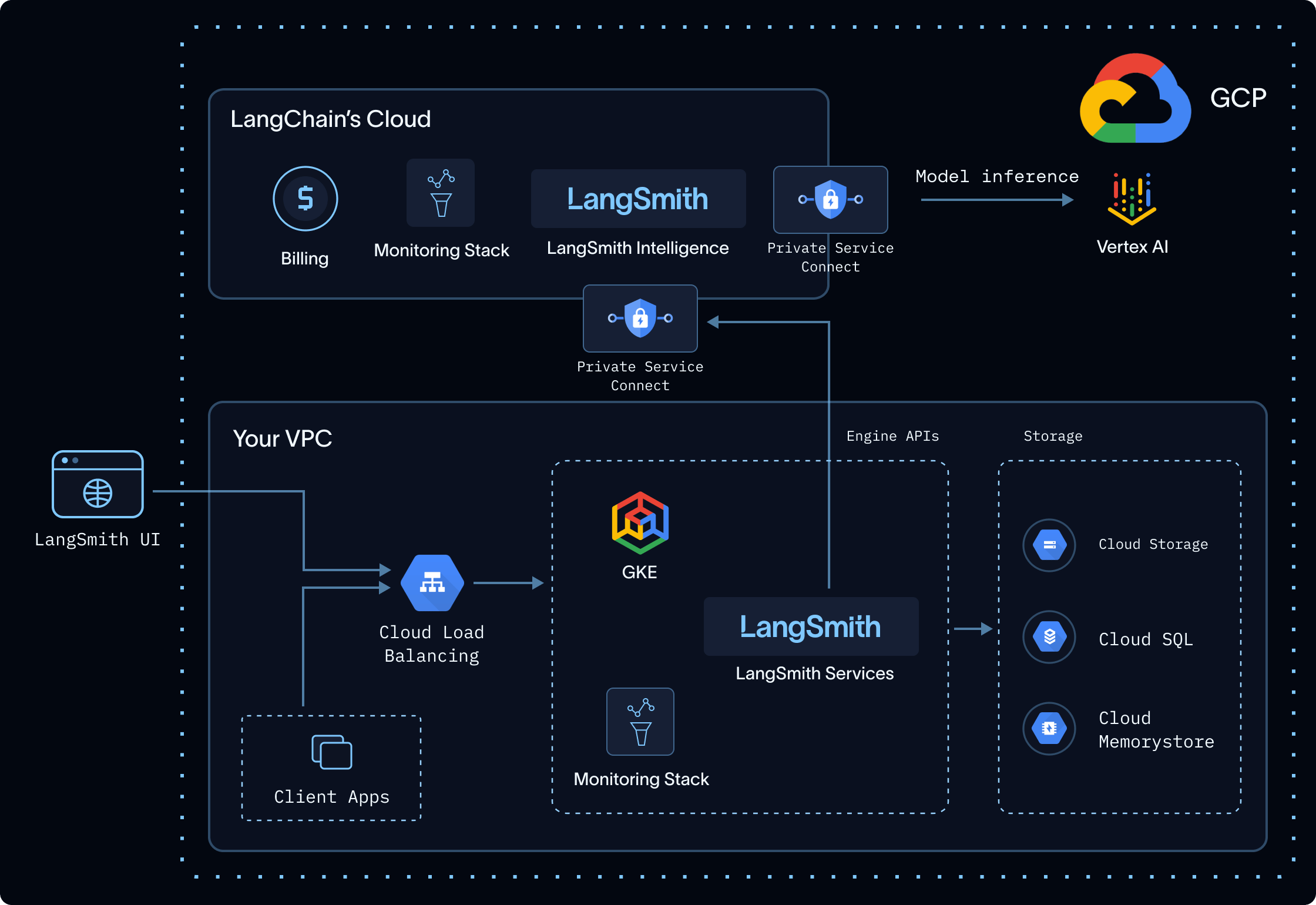
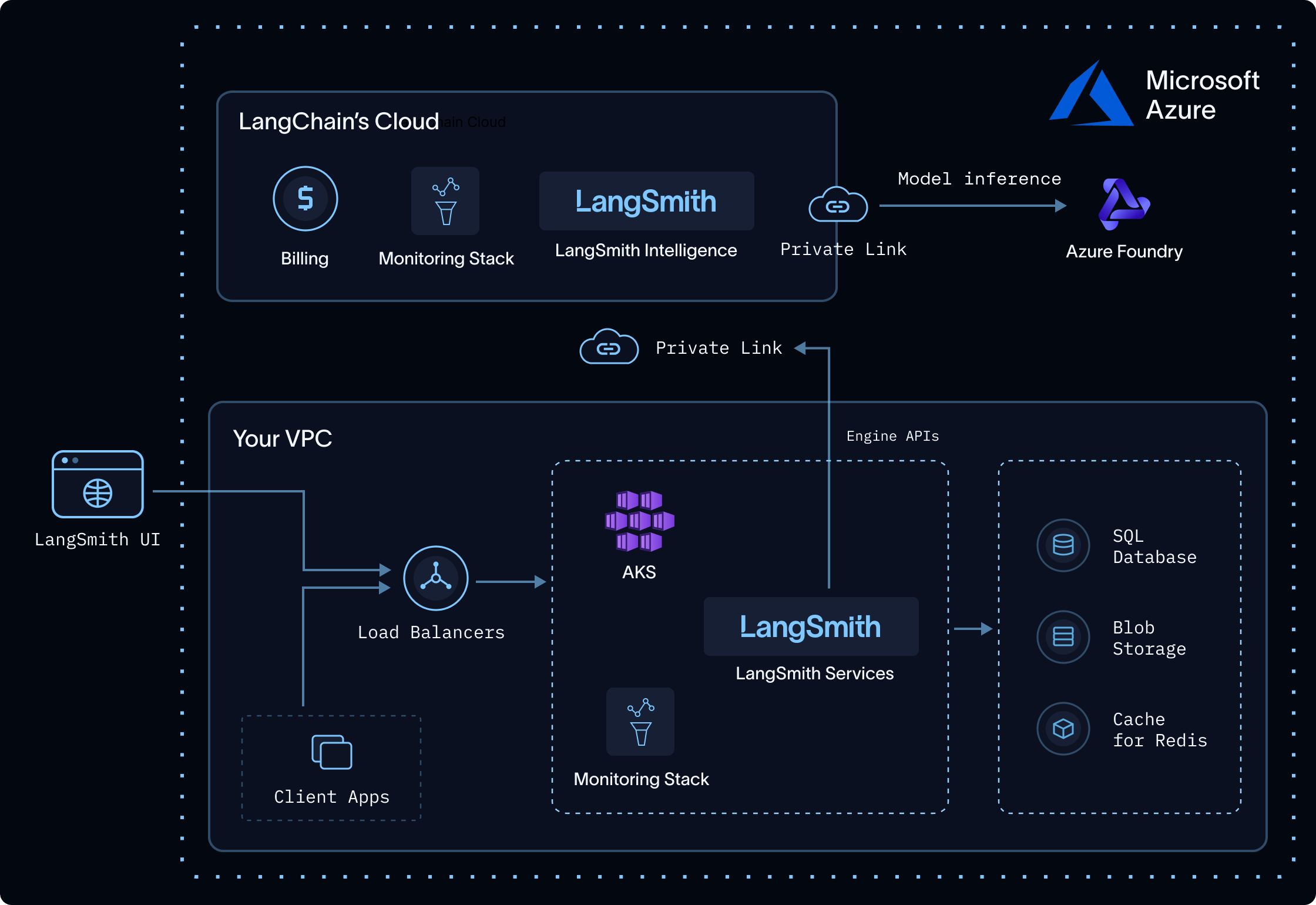
Engine’s inference is delivered through a LangChain-managed service, LangSmith Intelligence. The service is fully isolated from LangSmith and does not trace, store, or persist any customer data. The flow:- Your self-hosted deployment connects to LangSmith Intelligence over a private link (PrivateLink on AWS and Azure, Private Service Connect on GCP).
- LangSmith Intelligence runs models hosted within your cloud provider’s environment (Bedrock, Vertex, or Foundry), so no data leaves your CSP.
- The service records only request metadata for billing, plus telemetry needed to keep the service reliable.
AWS
GCP
Azure
Model selection and quality
Model selection drives much of what makes Engine effective. Engine uses different models, tuned differently, for each step of its work: clustering issues, diagnosing root cause against your code, generating a fix, and writing the evaluator that verifies it. LangChain tunes these models for both quality and token efficiency, and upgrades them as better models ship. Managed inference makes that possible. Because Engine always runs the model LangChain has tuned for each step, behavior stays consistent and improves as those models are upgraded. A bring-your-own-key setup would instead tie Engine to the models you have configured, so tuning and token efficiency would vary from request to request.What this means for your data
In a self-hosted deployment, Engine adds two data-locality guarantees on top of the controls common to every deployment:- Private networks only: all data transit happens over private link, never the public internet.
- In-CSP: models run inside your CSP, so data never leaves it.
See also
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.