


 Amazon Bedrock
Amazon Bedrock
 Anthropic
Anthropic
 Azure OpenAI
Azure OpenAI
 DeepSeek
DeepSeek
 Fireworks
Fireworks
 Google GeminiGoogle Vertex AI
Google GeminiGoogle Vertex AI
 Groq
Groq
 Mistral AI
Mistral AI
 OpenAIOpenAI compatible endpoint
OpenAIOpenAI compatible endpoint
 XAI
XAIAmazon Bedrock
Before you use this model, ensure you have AWS credentials or IAM role.Authentication
Amazon Bedrock supports two authentication methods. IAM trusted entity is the recommended approach because it avoids sharing long-lived AWS access keys with LangSmith.IAM trusted entity (recommended)
Not applicable for self-hosted LangSmith. Use Access Keys (or the Bedrock API Key) instead.
- Create an IAM role in your AWS account with permissions to invoke Bedrock models (e.g.,
bedrock:InvokeModel). - Add a trust policy that allows LangSmith’s AWS account (
808407022534) to assume the role, using your LangSmith workspace ID as the external ID:
-
In the LangSmith Playground, open the Bedrock provider’s secrets configuration by clicking the Key icon (the IAM Trusted Entity option is not available in the model configuration dropdown itself). Then expand the IAM Trusted Entity section and enter the ARN of the role you created.
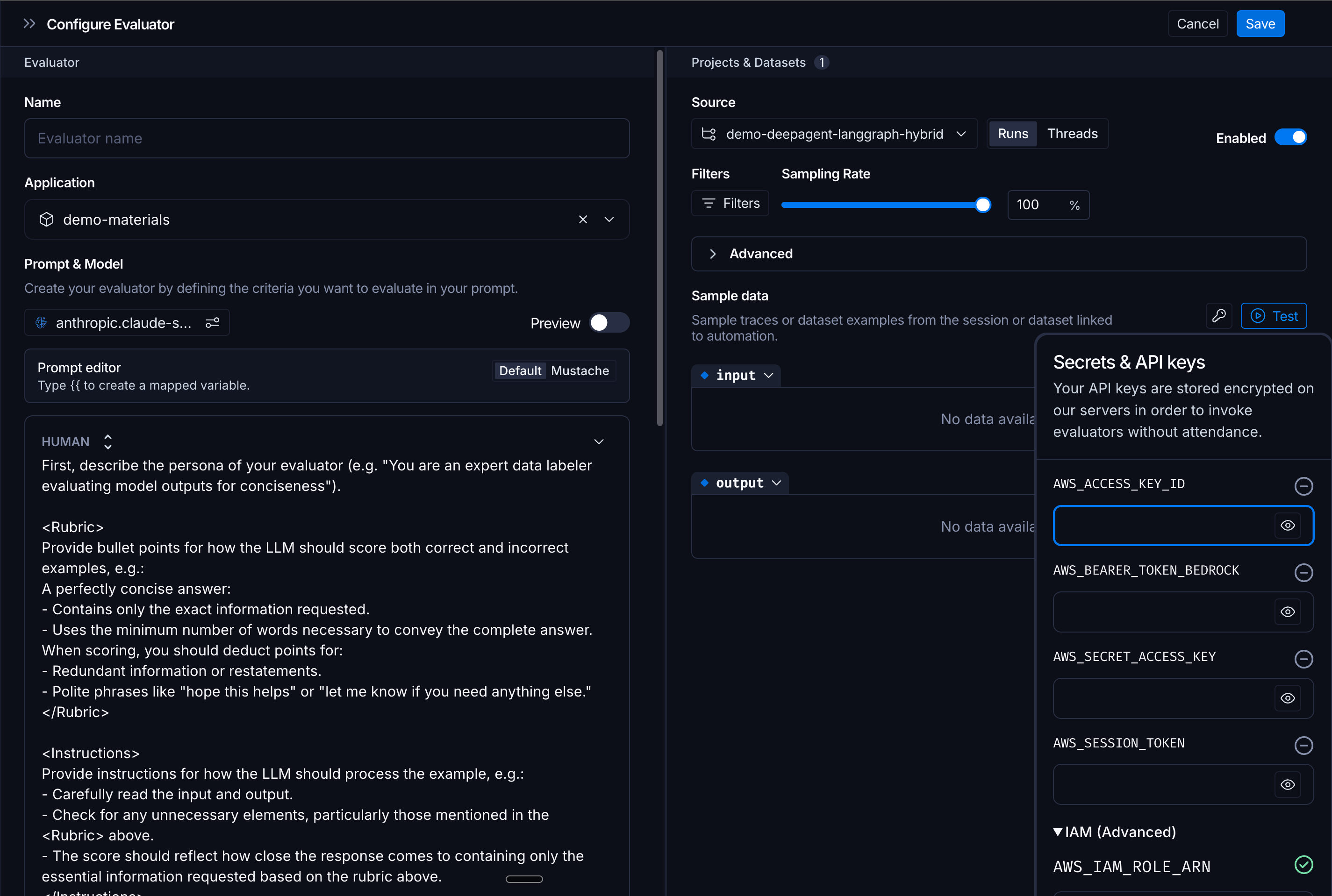
Access keys
Alternatively, you can authenticate with AWS access keys (AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY). Enter these in the Bedrock provider configuration in the Playground. This method is simpler to set up but less secure because it requires storing long-lived credentials.
Available models
AWS Bedrock provides access to foundation models from multiple providers:- Anthropic: Claude models.
- Amazon: Titan models.
- Cohere: Command models.
- Meta: Llama models.
- Others: Additional providers available based on region.
Configuration parameters
Parameters depend on the underlying model provider:For Anthropic models
Uses Anthropic configuration (see Anthropic section below).For Amazon Titan
AWS-specific settings
- Region: AWS region for model deployment.
Tool calling
Depends on underlying model:- Anthropic models:
auto,any. - Cohere models:
auto.
Anthropic
Before you use this model, ensure you have an Anthropic API key.Available models
Anthropic offers three tiers of models across their Claude generations:- Opus: Highest intelligence and capability.
- Sonnet: Balanced performance and cost.
- Haiku: Fast and cost-effective.
Configuration parameters
Temperature, Top P, and Top K are optional. When unchecked, Claude uses its internal defaults.
Extended Thinking
Available on supported Claude models. Enable the model to show reasoning before responding, similar to OpenAI’s o-series.
When enabled, responses include:
- A “thinking” section with the model’s reasoning.
- The final response.
Advanced options
- Base URL: Override API endpoint for custom deployments.
Tool calling
- Supported Tool Choices:
auto,any(requires at least one tool). - Parallel Execution: No (sequential only).
Azure OpenAI
Before you use this model, ensure you have Azure OpenAI credentials (endpoint + API key).Available models
Azure OpenAI provides the same model families as OpenAI:- GPT series: General-purpose chat models.
- o-series: Reasoning-focused models.
- Legacy models: GPT-3.5 and GPT-4 variants.
Configuration parameters
Azure OpenAI supports the same parameters as OpenAI:Standard parameters
Advanced parameters
Reasoning Effort: Available on reasoning-optimized models (o-series and newer GPT models). Service Tier: Available on newer models. Other parameters:- JSON Mode: Force valid JSON responses.
- Parallel Tool Calls: Execute multiple tools concurrently.
Azure-specific features
- Deployment Management: Models must be deployed before use.
- Regional Availability: Choose Azure regions for data residency.
- Content Filtering: Built-in content moderation and safety features.
- Managed Identity: Azure AD authentication support.
- Private Endpoints: VNet integration for secure access.
Tool calling
- Supported Tool Choices:
auto,required,none, or specific tool name. - Parallel Execution: Yes.
DeepSeek
Before you use this model, ensure you have a DeepSeek API key.Available models
DeepSeek offers general-purpose models, reasoning-optimized models (R-series), and coding-specialized models. For the current list of available models, refer to DeepSeek’s documentation.Configuration parameters
Fireworks
Before you use this model, ensure you have a Fireworks API key.Available models
Fireworks provides high-speed inference for popular open-source models and fine-tuned variants, including:- Llama: Meta’s Llama models in various sizes.
- Mixtral: Mistral’s mixture-of-experts models.
- Qwen: Alibaba’s multilingual models.
- DeepSeek: DeepSeek models.
- Other open models: Gemma, Phi, and more.
Configuration parameters
Tool calling
- Supported Tool Choices:
auto,required,none. - Parallel Execution: Yes.
Google Gemini
Before you use this model, ensure you have a Google AI API key.Available models
Google offers Gemini models in multiple tiers (Ultra, Pro, Flash) optimized for different use cases. For the current list of available models, refer to Google’s Gemini documentation.Configuration parameters
Tool calling
- Supported Tool Choices:
auto,any,none. - Parallel Execution: No.
Google Vertex AI
Before you use this model, ensure you have Google Cloud credentials.Available models
Google offers Gemini models in multiple tiers (Ultra, Pro, Flash) optimized for different use cases, plus other models available through Vertex AI. For the current list of available models, refer to the Vertex AI documentation.Configuration parameters
Advanced options
- Region Selection: Deploy in specific Google Cloud regions.
- Safety Settings: Configure content filtering thresholds.
Tool calling
- Supported Tool Choices:
auto,any,none. - Parallel Execution: No.
Groq
Before you use this model, ensure you have a Groq API key.Available models
Groq provides high-speed inference for popular open-source models including Llama, Mixtral, and Gemma variants. For the current list of available models, refer to Groq’s model documentation.Configuration parameters
Tool calling
- Supported Tool Choices:
auto,required,none. - Parallel Execution: Yes.
Mistral AI
Before you use this model, ensure you have a Mistral AI API key.Available models
Mistral offers models in multiple tiers (Large, Medium, Small) optimized for different performance and cost requirements. For the current list of available models, refer to Mistral’s documentation.Configuration parameters
Tool calling
- Supported Tool Choices:
auto,any,none. - Parallel Execution: No.
OpenAI
Before you use this model, ensure you have an OpenAI API key or Azure OpenAI credentials.Available models
OpenAI offers several model families with different capabilities and price points:- GPT series: General-purpose chat models with various size/capability tiers.
- o-series: Reasoning-focused models optimized for complex problem-solving.
- Legacy models: Older GPT-3.5 and GPT-4 variants.
Configuration parameters
Standard:
Advanced:
Reasoning Effort: Available on reasoning-optimized models (o-series and newer GPT models).
Controls reasoning depth before responding. Higher effort = better quality for complex tasks, longer latency.
When reasoning_effort is active (not
none), temperature, top_p, and penalties are automatically disabled.
Other parameters:
- JSON Mode: Force valid JSON responses.
- Responses API: Improved streaming (default: enabled).
- Parallel Tool Calls: Execute multiple tools concurrently.
Tool calling
- Supported Tool Choices:
auto,required,none, or specific tool name - Parallel Execution: Yes
OpenAI Compatible Endpoint
Authentication varies by endpoint. Common options:- API key: stored as a workspace secret and forwarded as
Authorization: Bearer <key>. - None: for unauthenticated local endpoints (for example, Ollama on
localhost). - OAuth2
client_credentials: stored on the model configuration. LangSmith mints a short-lived bearer at request time and refreshes it before expiry. See OAuth client credentials.
Configuration
Required:- Base URL: Your endpoint URL (e.g.,
https://your-endpoint.com/v1). - Model Name: Your model identifier.
- Self-hosted open-source inference servers
- Model routing proxies
- Custom model endpoints
Configuration parameters
All OpenAI-compatible parameters:
Advanced:
- JSON Mode: If endpoint supports it.
- Streaming: If endpoint supports it.
- Function Calling: If endpoint implements OpenAI format.
Tool calling
- Supported Tool Choices:
auto,required,none(if endpoint supports). - Parallel Execution: Yes (if endpoint supports).
Example endpoints
Local Ollama:XAI
Before you use this model, ensure you have an xAI API key.Available models
xAI offers Grok models in multiple sizes for different use cases. For the current list of available models, refer to xAI’s documentation.Configuration parameters
Standard OpenAI-compatible parameters:Tool calling
- Supported Tool Choices: OpenAI-compatible.
- Parallel Execution: Yes (if supported).
Common Configuration Across All Providers
Extra Parameters
All providers support a JSON editor for extra parameters not exposed in the UI:- Provider-specific beta features
- Advanced parameters not yet in UI
- Custom metadata for tracking
Rate Limiting
Requests Per Second (RPS) - Available for all providers when running over datasets:- Range: 0 - 500 RPS
- Purpose: Respect API rate limits, control costs
- Default: Varies by provider
Next steps
Configure prompt settings
Learn how to create and manage model configurations in the Playground.
Create a prompt
Get started building prompts with your chosen model provider.
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.