

Interpreters require
@langchain/quickjs.Quickstart
Dynamic subagents require interpreter middleware. Install and wire up the interpreter first. The built-in general-purpose subagent handles basic fan-out without extra configuration.Use with a coding agent
The fastest way to try dynamic subagents is withdcode, the LangChain terminal coding agent built on a Deep Agent. It ships with the code interpreter enabled, so dynamic subagents work out of the box with nothing to wire up.
Install dcode:
task tool, the agent writes an orchestration script that calls the built-in task() global and runs it in the code interpreter. For example: “Run a workflow to review every file in src/ for SQL injection.”
As subagents spawn, dcode shows them live in the dynamic subagents panel, grouped into phases by dispatch.
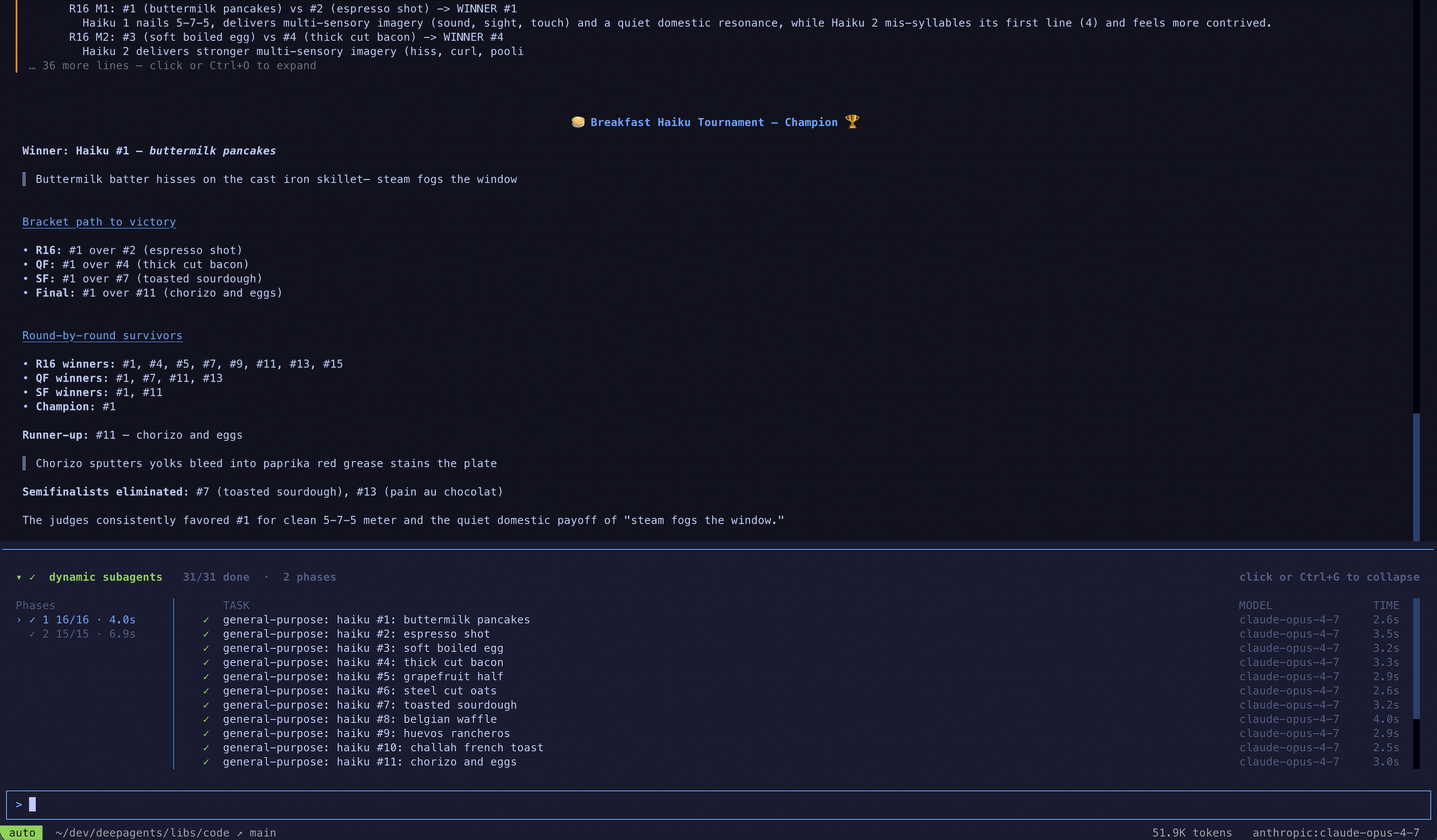
dcode is the fastest way to try this, but you can also use dynamic subagents in the coding agent of your choice over ACP (for example, Zed).
How it works
When an agent has subagents and interpreter middleware, the interpreter exposes a built-intask() global that dispatches subagents from code. A task spanning many independent units (reviewing every file in a directory, triaging a batch of tickets) becomes a loop that fans the work out, so it runs deterministically instead of one model-chosen tool call at a time.
Subagent orchestration also supports recursive language model (RLM) workflows, the approach described in the Recursive Language Models paper: keep the working set in interpreter variables, select slices, call subagents with task(), and synthesize the results.
Many orchestration workflows combine dynamic subagents with programmatic tool calling (PTC): use tools.* from interpreter code to discover or filter inputs, then dispatch subagents with task(). PTC is off by default; enable it with an explicit allowlist on interpreter middleware.
task() is a capability bridge into subagent execution, similar to PTC for tools. For isolation defaults, approval boundaries, and middleware options, see Security and Configuration.
task() takes the following inputs:
description: The prompt for the subagentsubagentType: Which configured subagent to runresponseSchema(optional): Structured output
task() runs a full agentic loop and resolves to the subagent’s result:
responseSchema, the resolved value is already a typed JavaScript object; only call JSON.parse if a subagent intentionally returned a JSON string.
Patterns
The agent picks a strategy from the shape of the task; these emerge from how it writes interpreter code, not from configuration, and the subagents you make available determine what it can do. Every pattern shares the same orchestration approach: hold work in JS variables, dispatch subagents withtask(), and combine results in code. The diagrams below show the common shapes, each with a runnable example.
Classify and act
Items are classified first, then each item is handled by a specialized subagent based on its classification. This lets you process mixed inputs where different items need different expertise. Use cases: Triaging support tickets, error logs, user feedback, or any batch of items that need different handling depending on their type.Example: classify and act
Example: classify and act
What you configureWhat the agent writes
Fan-out and synthesize
The agent dispatches the same kind of work across many items in parallel, then combines the results. Use cases: Code review across a directory, analyzing a batch of documents, processing log files, running the same check across many services. Discovering files from interpreter code requires programmatic tool calling (PTC). Enableglob in the PTC allowlist on interpreter middleware.
Example: fan-out and synthesize
Example: fan-out and synthesize
What you configureWhat the agent writes
Adversarial verification
A two-pass pattern. The first pass produces findings. The second pass sends each finding to independent verifiers, and only findings that survive agreement are kept. This reduces false positives when confidence matters more than speed. Use cases: Security audits where false positives are costly, compliance checks, any review where you need high confidence in findings.Example: adversarial verification
Example: adversarial verification
What you configureWhat the agent writes
Generate and filter
Multiple subagents generate independent solutions to the same problem. The agent compares, scores, and filters the results in code, keeping only the best. Use cases: Architecture proposals, refactoring strategies, content variations, any task where exploring multiple options before committing produces a better outcome.Example: generate and filter
Example: generate and filter
What you configureWhat the agent writes
Tournament
Variations are compared head-to-head by a judge subagent, with winners advancing through elimination rounds. Use cases: Optimization under subjective criteria, style selection, choosing between competing implementations.Example: tournament
Example: tournament
What you configureWhat the agent writes
Loop until done
The agent runs a discovery loop, deduplicating against what it has already found, until no new results appear. Useful when the scope of the work is not known upfront. Use cases: Exhaustive search, dead code detection, dependency audits, any sweep where you want completeness rather than a fixed number of results.Example: loop until done
Example: loop until done
What you configureWhat the agent writes
Disable dynamic subagents
Subagent dispatch is on by default whenever the agent has subagents. Disable it if you want subagents to be available only through the normaltask tool path. For other middleware options, see Configuration on the interpreters page.
See also
- Interpreters: QuickJS setup, programmatic tool calling, persistence, security, and middleware configuration
- Subagents: Configure subagent names, descriptions, and system prompts
- Event streaming: Stream updates from the coordinator and delegated subagents
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.