If your graph contains subgraphs, you only need to provide the checkpointer when compiling the parent graph. LangGraph will automatically propagate the checkpointer to the child subgraphs.
import { StateGraph, StateSchema, START, MemorySaver } from "@langchain/langgraph";import { z } from "zod/v4";const State = new StateSchema({ foo: z.string() });const subgraphBuilder = new StateGraph(State) .addNode("subgraph_node_1", (state) => { return { foo: state.foo + "bar" }; }) .addEdge(START, "subgraph_node_1");const subgraph = subgraphBuilder.compile();const builder = new StateGraph(State) .addNode("node_1", subgraph) .addEdge(START, "node_1");const checkpointer = new MemorySaver();const graph = builder.compile({ checkpointer });
You can configure subgraph-specific checkpointing behavior. See subgraph persistence for details on persistence levels including interrupt support and stateful continuations.
Use long-term memory to store user-specific or application-specific data across conversations.
import { InMemoryStore, StateGraph } from "@langchain/langgraph";const store = new InMemoryStore();const builder = new StateGraph(...);const graph = builder.compile({ store });
Once you compile a graph with a store, LangGraph automatically injects the store into your node functions. The recommended way to access the store is through the Runtime object.
import { StateGraph, StateSchema, MessagesValue, GraphNode, START } from "@langchain/langgraph";const State = new StateSchema({ messages: MessagesValue,});const callModel: GraphNode<typeof State> = async (state, runtime) => { const userId = runtime.context?.userId; const namespace = [userId, "memories"]; // Search for relevant memories const memories = await runtime.store?.search(namespace, { query: state.messages.at(-1)?.content, limit: 3, }); const info = memories?.map((d) => d.value.data).join("\n") || ""; // ... Use memories in model call // Store a new memory await runtime.store?.put(namespace, crypto.randomUUID(), { data: "User prefers dark mode" });};const builder = new StateGraph(State) .addNode("call_model", callModel) .addEdge(START, "call_model");const graph = builder.compile({ store });// Pass context at invocation timeawait graph.invoke( { messages: [{ role: "user", content: "hi" }] }, { configurable: { thread_id: "1" }, context: { userId: "1" } });
Enable semantic search in your graph’s memory store to let graph agents search for items in the store by semantic similarity.
import { OpenAIEmbeddings } from "@langchain/openai";import { InMemoryStore } from "@langchain/langgraph";// Create store with semantic search enabledconst embeddings = new OpenAIEmbeddings({ model: "text-embedding-3-small" });const store = new InMemoryStore({ index: { embeddings, dims: 1536, },});await store.put(["user_123", "memories"], "1", { text: "I love pizza" });await store.put(["user_123", "memories"], "2", { text: "I am a plumber" });const items = await store.search(["user_123", "memories"], { query: "I'm hungry", limit: 1,});
InMemoryStore is suitable for development. For production, use a persistent store like PostgresStore, MongoDBStore, or RedisStore.
Long-term memory with semantic search
InMemoryStore
MongoDB (manual embedding)
MongoDB (auto embedding)
import { OpenAIEmbeddings, ChatOpenAI } from "@langchain/openai";import { StateGraph, StateSchema, MessagesValue, GraphNode, START, InMemoryStore } from "@langchain/langgraph";const State = new StateSchema({ messages: MessagesValue,});const model = new ChatOpenAI({ model: "gpt-5.4-mini" });// Create store with semantic search enabledconst embeddings = new OpenAIEmbeddings({ model: "text-embedding-3-small" });const store = new InMemoryStore({ index: { embeddings, dims: 1536, }});await store.put(["user_123", "memories"], "1", { text: "I love pizza" });await store.put(["user_123", "memories"], "2", { text: "I am a plumber" });const chat: GraphNode<typeof State> = async (state, runtime) => { // Search based on user's last message const items = await runtime.store.search( ["user_123", "memories"], { query: state.messages.at(-1)?.content, limit: 2 } ); const memories = items.map(item => item.value.text).join("\n"); const memoriesText = memories ? `## Memories of user\n${memories}` : ""; const response = await model.invoke([ { role: "system", content: `You are a helpful assistant.\n${memoriesText}` }, ...state.messages, ]); return { messages: [response] };};const builder = new StateGraph(State) .addNode("chat", chat) .addEdge(START, "chat");const graph = builder.compile({ store });const stream = await graph.streamEvents( { messages: [{ role: "user", content: "I'm hungry" }] }, { version: "v3" });for await (const message of stream.messages) { for await (const token of message.text) { process.stdout.write(token); }}
import { ChatOpenAI, OpenAIEmbeddings } from "@langchain/openai";import { MongoDBStore } from "@langchain/langgraph-checkpoint-mongodb";import { StateGraph, StateSchema, MessagesValue, GraphNode, START } from "@langchain/langgraph";const State = new StateSchema({ messages: MessagesValue,});const model = new ChatOpenAI({ model: "gpt-5.4-mini" });// Create store with semantic search enabledconst MONGODB_URI = "mongodb://user:password@localhost:27017";const store = await MongoDBStore.fromConnString(MONGODB_URI, { dbName: "langgraph", collectionName: "store", embeddings: new OpenAIEmbeddings({ model: "text-embedding-3-small" }), indexConfig: { name: "store_vector_index", dims: 1536, embeddingKey: "text", },});await store.put(["user_123", "memories"], "1", { text: "I love pizza" });await store.put(["user_123", "memories"], "2", { text: "I am a plumber" });const chat: GraphNode<typeof State> = async (state, runtime) => { // Search based on user's last message const items = await runtime.store.search( ["user_123", "memories"], { query: state.messages.at(-1)?.content, limit: 2 } ); const memories = items.map(item => item.value.text).join("\n"); const memoriesText = memories ? `## Memories of user\n${memories}` : ""; const response = await model.invoke([ { role: "system", content: `You are a helpful assistant.\n${memoriesText}` }, ...state.messages, ]); return { messages: [response] };};const builder = new StateGraph(State) .addNode("chat", chat) .addEdge(START, "chat");const graph = builder.compile({ store });const stream = await graph.streamEvents( { messages: [{ role: "user", content: "I'm hungry" }] }, { version: "v3" });for await (const message of stream.messages) { for await (const token of message.text) { process.stdout.write(token); }}
Auto embedding requires MongoDB Atlas. MongoDB generates embeddings server-side via Voyage AI. See the Automated Embedding documentation for more information.
import { StateGraph, StateSchema, MessagesValue, GraphNode, START } from "@langchain/langgraph";import { MongoDBStore } from "@langchain/langgraph-checkpoint-mongodb";import { ChatOpenAI } from "@langchain/openai";const State = new StateSchema({ messages: MessagesValue,});const model = new ChatOpenAI({ model: "gpt-5.4-mini" });// Auto embedding: no embeddings instance needed.// Configure the Voyage AI model and the field path MongoDB will read server-side.const MONGODB_URI = "mongodb://user:password@localhost:27017";const store = await MongoDBStore.fromConnString(MONGODB_URI, { dbName: "langgraph", collectionName: "store", indexConfig: { name: "store_vector_index", path: "value.content", // MongoDB reads this field and embeds it server-side model: "voyage-4", // Voyage AI model used by MongoDB Atlas },});// Values must have the content field matching the configured path (value.content)await store.put(["user_123", "memories"], "1", { content: "I love pizza" });await store.put(["user_123", "memories"], "2", { content: "I am a plumber" });const chat: GraphNode<typeof State> = async (state, runtime) => { // MongoDB generates the query embedding server-side const items = await runtime.store.search( ["user_123", "memories"], { query: state.messages.at(-1)?.content, limit: 2 } ); const memories = items.map(item => item.value.content).join("\n"); const memoriesText = memories ? `## Memories of user\n${memories}` : ""; const response = await model.invoke([ { role: "system", content: `You are a helpful assistant.\n${memoriesText}` }, ...state.messages, ]); return { messages: [response] };};const builder = new StateGraph(State) .addNode("chat", chat) .addEdge(START, "chat");const graph = builder.compile({ store });const stream = await graph.streamEvents( { messages: [{ role: "user", content: "I'm hungry" }] }, { version: "v3" });for await (const message of stream.messages) { for await (const token of message.text) { process.stdout.write(token); }}
Most LLMs have a maximum supported context window (denominated in tokens). One way to decide when to truncate messages is to count the tokens in the message history and truncate whenever it approaches that limit. If you’re using LangChain, you can use the trim messages utility and specify the number of tokens to keep from the list, as well as the strategy (e.g., keep the last maxTokens) to use for handling the boundary.To trim message history, use the trimMessages function:
You can delete messages from the graph state to manage the message history. This is useful when you want to remove specific messages or clear the entire message history.To delete messages from the graph state, you can use the RemoveMessage. For RemoveMessage to work, you need to use a state key with messagesStateReducerreducer, like MessagesValue.To remove specific messages:
import { RemoveMessage } from "@langchain/core/messages";const deleteMessages = (state) => { const messages = state.messages; if (messages.length > 2) { // remove the earliest two messages return { messages: messages .slice(0, 2) .map((m) => new RemoveMessage({ id: m.id })), }; }};
When deleting messages, make sure that the resulting message history is valid. Check the limitations of the LLM provider you’re using. For example:
Some providers expect message history to start with a user message
Most providers require assistant messages with tool calls to be followed by corresponding tool result messages.
[['human', "hi! I'm bob"]][['human', "hi! I'm bob"], ['ai', 'Hi Bob! How are you doing today? Is there anything I can help you with?']][['human', "hi! I'm bob"], ['ai', 'Hi Bob! How are you doing today? Is there anything I can help you with?'], ['human', "what's my name?"]][['human', "hi! I'm bob"], ['ai', 'Hi Bob! How are you doing today? Is there anything I can help you with?'], ['human', "what's my name?"], ['ai', 'Your name is Bob.']][['human', "what's my name?"], ['ai', 'Your name is Bob.']]
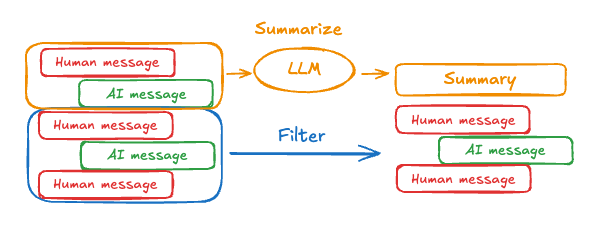
The problem with trimming or removing messages, as shown above, is that you may lose information from culling of the message queue. Because of this, some applications benefit from a more sophisticated approach of summarizing the message history using a chat model.Prompting and orchestration logic can be used to summarize the message history. For example, in LangGraph you can include a summary key in the state alongside the messages key:
import { StateSchema, MessagesValue, GraphNode } from "@langchain/langgraph";import { z } from "zod/v4";const State = new StateSchema({ messages: MessagesValue, summary: z.string().optional(),});
Then, you can generate a summary of the chat history, using any existing summary as context for the next summary. This summarizeConversation node can be called after some number of messages have accumulated in the messages state key.
import { RemoveMessage, HumanMessage } from "@langchain/core/messages";const summarizeConversation: GraphNode<typeof State> = async (state) => { // First, we get any existing summary const summary = state.summary || ""; // Create our summarization prompt let summaryMessage: string; if (summary) { // A summary already exists summaryMessage = `This is a summary of the conversation to date: ${summary}\n\n` + "Extend the summary by taking into account the new messages above:"; } else { summaryMessage = "Create a summary of the conversation above:"; } // Add prompt to our history const messages = [ ...state.messages, new HumanMessage({ content: summaryMessage }) ]; const response = await model.invoke(messages); // Delete all but the 2 most recent messages const deleteMessages = state.messages .slice(0, -2) .map(m => new RemoveMessage({ id: m.id })); return { summary: response.content, messages: deleteMessages };};
Full example: summarize messages
import { ChatAnthropic } from "@langchain/anthropic";import { SystemMessage, HumanMessage, RemoveMessage,} from "@langchain/core/messages";import { StateGraph, StateSchema, MessagesValue, GraphNode, ConditionalEdgeRouter, START, END, MemorySaver,} from "@langchain/langgraph";import * as z from "zod";const memory = new MemorySaver();// We will add a `summary` attribute (in addition to `messages` key)const GraphState = new StateSchema({ messages: MessagesValue, summary: z.string().default(""),});// We will use this model for both the conversation and the summarizationconst model = new ChatAnthropic({ model: "claude-haiku-4-5-20251001" });// Define the logic to call the modelconst callModel: GraphNode<typeof GraphState> = async (state) => { // If a summary exists, we add this in as a system message const { summary } = state; let { messages } = state; if (summary) { const systemMessage = new SystemMessage({ id: crypto.randomUUID(), content: `Summary of conversation earlier: ${summary}`, }); messages = [systemMessage, ...messages]; } const response = await model.invoke(messages); // We return an object, because this will get added to the existing state return { messages: [response] };};// We now define the logic for determining whether to end or summarize the conversationconst shouldContinue: ConditionalEdgeRouter<typeof GraphState, "summarize_conversation"> = (state) => { const messages = state.messages; // If there are more than six messages, then we summarize the conversation if (messages.length > 6) { return "summarize_conversation"; } // Otherwise we can just end return END;};const summarizeConversation: GraphNode<typeof GraphState> = async (state) => { // First, we summarize the conversation const { summary, messages } = state; let summaryMessage: string; if (summary) { // If a summary already exists, we use a different system prompt // to summarize it than if one didn't summaryMessage = `This is summary of the conversation to date: ${summary}\n\n` + "Extend the summary by taking into account the new messages above:"; } else { summaryMessage = "Create a summary of the conversation above:"; } const allMessages = [ ...messages, new HumanMessage({ id: crypto.randomUUID(), content: summaryMessage }), ]; const response = await model.invoke(allMessages); // We now need to delete messages that we no longer want to show up // I will delete all but the last two messages, but you can change this const deleteMessages = messages .slice(0, -2) .map((m) => new RemoveMessage({ id: m.id! })); if (typeof response.content !== "string") { throw new Error("Expected a string response from the model"); } return { summary: response.content, messages: deleteMessages };};// Define a new graphconst workflow = new StateGraph(GraphState) // Define the conversation node and the summarize node .addNode("conversation", callModel) .addNode("summarize_conversation", summarizeConversation) // Set the entrypoint as conversation .addEdge(START, "conversation") // We now add a conditional edge .addConditionalEdges( // First, we define the start node. We use `conversation`. // This means these are the edges taken after the `conversation` node is called. "conversation", // Next, we pass in the function that will determine which node is called next. shouldContinue, ) // We now add a normal edge from `summarize_conversation` to END. // This means that after `summarize_conversation` is called, we end. .addEdge("summarize_conversation", END);// Finally, we compile it!const app = workflow.compile({ checkpointer: memory });
const config = { configurable: { thread_id: "1", // optionally provide an ID for a specific checkpoint, // otherwise the latest checkpoint is shown // checkpoint_id: "1f029ca3-1f5b-6704-8004-820c16b69a5a" },};await graph.getState(config);
If you are using any database-backed persistence implementation (such as Postgres, Redis, or Oracle) to store short and/or long-term memory, you will need to run migrations to set up the required schema before you can use it with your database.By convention, most database-specific libraries define a setup() method on the checkpointer or store instance that runs the required migrations. However, you should check with your specific implementation of BaseCheckpointSaver or BaseStore to confirm the exact method name and usage.We recommend running migrations as a dedicated deployment step, or you can ensure they’re run as part of server startup.
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.