

RAG patterns
Deep Agents allows you to orchestrate retrieval, analysis, and synthesis in several ways:- Skills-guided retrieval: The user asks a question. The agent loads a relevant skill that describes how to search your corpus (which index to use, query formulation, citation format). The agent calls your retrieval tool following that guidance, then synthesizes an answer.
- Rubric-checked grounding: The user asks a question. The agent retrieves evidence and drafts an answer. A grader sub-agent, configured with
RubricMiddleware, evaluates whether the response is grounded in the retrieved source material. The agent revises until the rubric passes or an iteration cap is reached. - Todo-driven investigation: The user asks a question. If you opt into task planning, the agent uses the planning tool to create a todo list of documentation pages or search queries to investigate. It retrieves results for each item, then synthesizes a response from the collected evidence.
- Retrieve, offload, and delegate: The user asks a question. The agent retrieves matching chunks and writes them to the filesystem backend rather than keeping full text in the orchestrator context. Subagents read, search, and summarize individual files in parallel. For large documents, the agent can paginate through files with built-in search tools or run a code interpreter to produce tables, timelines, or visuals from source data.
Why retrieval matters
A language model on its own does not have access to your documentation. Ask it about a specific API that changed recently, and it answers from training data: often plausible, sometimes wrong, and never grounded in your source of truth. Even when documentation is available, you generally cannot just fit it all into the context window. You therefore must select only the passages relevant to a given question, which in itself is a non-trivial task. This tutorial uses one question throughout:How do I stream intermediate tool results from a subagent?Pass that question to a Deep Agent with no custom tools and no access to the documentation corpus, to see what the model comes up with:
What you will build
- Index: Load the LangChain documentation into a vector store.
- Search: Build a custom tool that runs vector similarity search and writes each retrieved chunk to the agent filesystem.
- Analyze: Delegate file analysis to a subagent that reads the file and returns a focused summary.
- Synthesize: Use the main agent to get the final answer from subagent reports.
Prerequisites
API keys for:- A chat model integration for the agent
- OpenAI (or another embeddings integration) for indexing
Setup
1
Create project directory
2
Initialize the project
npm
3
Install dependencies
npm
@langchain/<provider> package for the model you select in the code examples below (Google, OpenAI, and Anthropic are included above).4
Set API keys
Export keys in your shell, or create a Or in Use the environment variable that matches the model provider in your code (
.env file in the project directory. The code loads .env automatically with import "dotenv/config" (added in the indexing step below)..env:ANTHROPIC_API_KEY for Claude, GOOGLE_API_KEY for Gemini, OPENAI_API_KEY for OpenAI).5
Set up LangSmith
RAG applications run retrieval and generation in sequence. When you run the examples in this tutorial, LangSmith logs a trace for each query so you can inspect retrieval, tool calls, and model responses.
After you sign up for LangSmith, set your environment variables to start logging traces:
Index LangChain documentation
In the indexing step, you’ll take the source content and convert chunks of it into numerical representations. This numerical representation captures the semantic meaning of the chunk. Storing a mapping of these numerical representations and the document chunks in aVectorStore allows you to efficiently retrieve relevant content when a user sends a query based on its own numerical representation.
Indexing commonly works in four steps:
- Load: Load your data sources into
Documentobjects. - Split: Use text splitters to break large
Documents into smaller chunks. This is useful both for indexing data and passing it to a model, as large chunks are harder to search over and either do not fit in a model’s finite context window or use more tokens than necessary. - Embed: Embeddings models convert each chunk into a numeric vector that captures its meaning, enabling similarity search over your content.
- Store: Use a VectorStore to index chunks and their embeddings for retrieval.
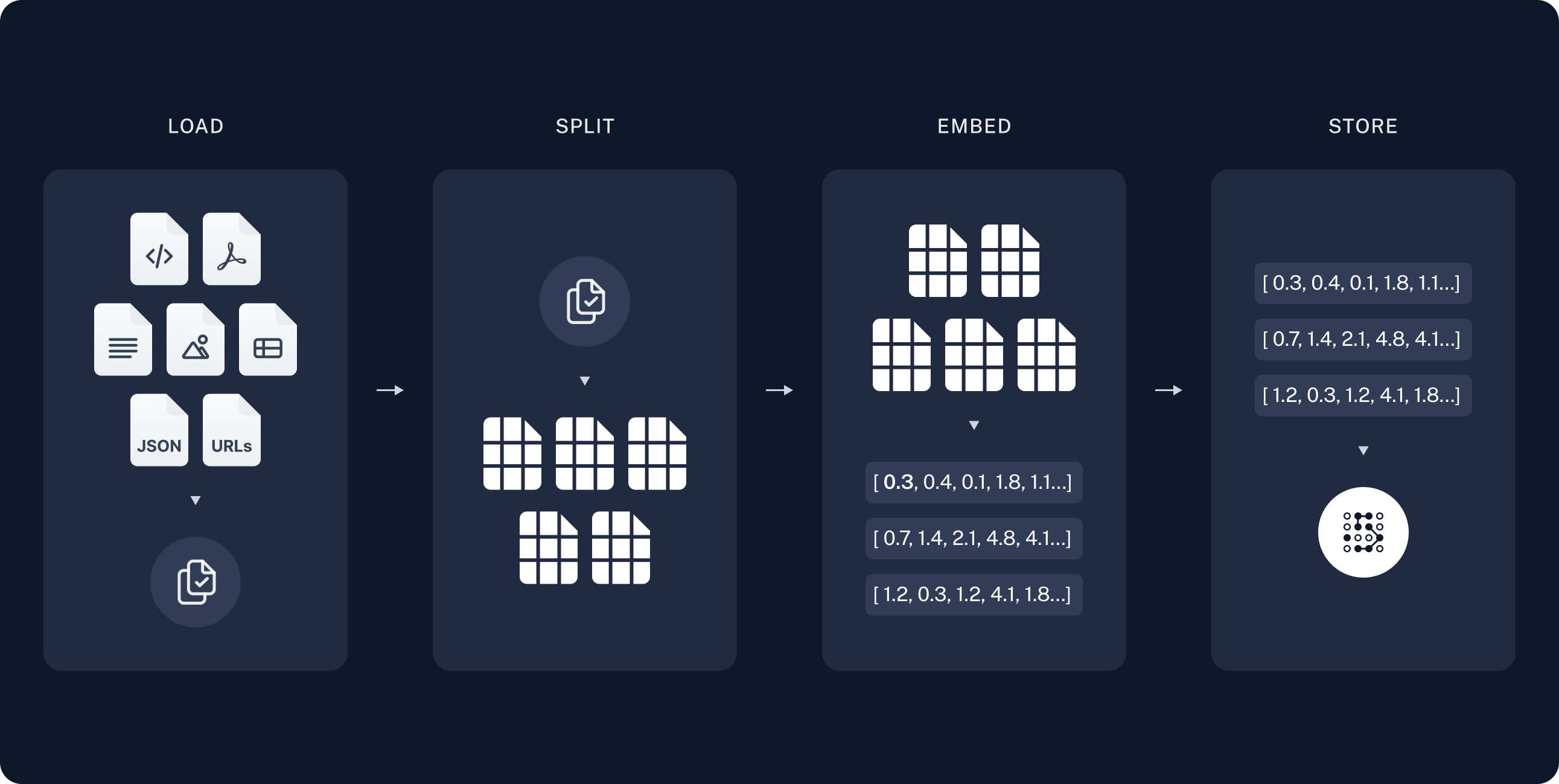
VectorStore. The agent searches this index at runtime; it does not re-fetch the full site on every question.
LangChain publishes markdown at https://docs.langchain.com/{path}.md. This tutorial indexes a curated list of open source documentation paths. You can expand DOC_PATHS or parse URLs from llms.txt to cover more pages.
Create agent.ts:
For a more detailed tutorial on indexing, vector stores, and retrieval, see Semantic search.
Load documents
Start by loading LangChain documentation pages into a list of Document objects. Usefetch to retrieve markdown from https://docs.langchain.com/{path}.md for each path in DOC_PATHS.
Split documents
The loaded documentation is long with over 100k tokens total, which makes it too large to fit into the context window of many models. Even for those models that could fit the full corpus in their context window, models can struggle to find information in very long inputs. Using the context window for large amounts of content is also not token efficient. For ease of use, split theDocument objects into chunks. These chunks will be used for embedding and vector storage in the next steps.
Use the RecursiveCharacterTextSplitter to recursively split the documents using common separators like new lines, until each chunk is the appropriate size.
RecursiveCharacterTextSplitter is the recommended TextSplitter for generic text use cases.
Select an embeddings model
An embedding is a numeric vector that captures the meaning of each documentation chunk. An Embeddings model converts those chunks into vectors so that similar meanings land close together in vector space, enabling you to retrieve relevant sections when a user asks a question. You can choose from many different embedding integrations which all use the same Interface:- OpenAI
- Azure
- AWS
- VertexAI
- MistralAI
- Cohere
Store chunks and embeddings in VectorStore
AVectorStore persists document chunks and their embeddings, enabling similarity search to retrieve relevant sections when a user asks a question.
You can choose from many different vector store integrations which all use the same Interface.
Use the embeddings model that you selected in the previous step to configure your VectorStore:
- Memory
- MongoDB
- Pinecone
- Qdrant
- Redis
vector_store you initialized above:
- Retrieve: Given a user input, relevant splits are retrieved from storage using a Retriever.
- Generate: A model produces an answer using a prompt that includes both the question and the retrieved data.
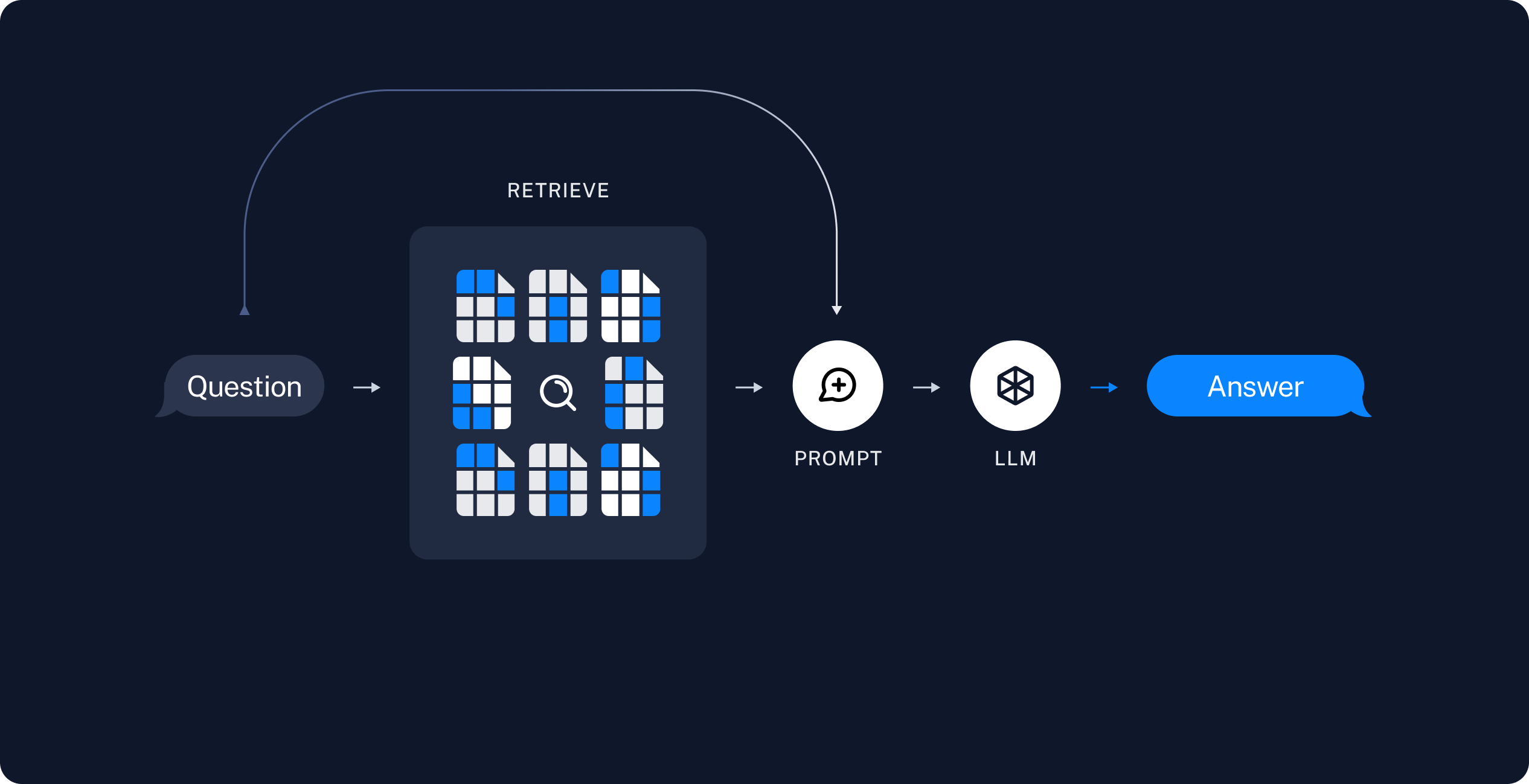
Build the agent
Add this code toagent.ts:
1
Add the search tool
The
search_documentation tool runs similarity search against the indexed corpus, then writes each retrieved chunk to the agent filesystem under /retrieved/{batch_id}/. It returns file paths so the orchestrator can delegate analysis without loading full chunk text into its context.The tool writes retrieved chunks to the agent backend with backend.uploadFiles(). Pass the same backend instance to createDeepAgent so built-in filesystem tools such as read_file and grep can read the saved paths.2
Add prompts
Add the orchestrator workflow and subagent prompt templates to
agent.ts:3
Create the agent
Add model initialization and agent creation to The main agent keeps the
agent.ts:search_documentation tool. The chunk-analyst subagent uses built-in filesystem tools to read chunk files but does not search the vector store directly.Run the agent
Run the RAG agent with the example query:- Calls
search_documentationwith a query about subagent streaming. - Receives file paths such as
/retrieved/a1b2c3d4/chunk_1.md. - Launches one or more
task()calls tochunk-analyst, each scoped to a single chunk file. - Synthesizes a final answer with links to the relevant documentation pages.
Security considerations
No prompt or delimiter strategy fully prevents indirect prompt injection. The orchestrator and subagent prompts in this tutorial ask the model to treat retrieved content as data only, and the search tool prefixes chunks with a# Source: header so analysts can distinguish metadata from body content. These patterns can help in some cases, but they do not provide reliable protection.
Validate agent outputs before surfacing them to users. Check that answers cite expected documentation paths and that claims match the retrieved source material.
For more on this topic, see research on prompt injection.
Full code
The following is the complete script for the agent: Save asagent.ts and run with npx tsx agent.ts:
Next steps
You implemented one RAG pattern withcreateDeepAgent. Combine it with other Deep Agents capabilities or try a different pattern from RAG patterns:
- Add Skills to package retrieval workflows and domain-specific search guidance
- Use Grading rubrics to verify answers are grounded in retrieved source material
- Evaluate a RAG application with LangSmith datasets and evaluators
- Read Context engineering for offloading and subagent isolation strategies
- Deploy your application with LangSmith Deployment
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.