

- Tracking agent behavior with logging, analytics, and debugging.
- Transforming prompts, tool selection, and output formatting.
- Adding retries, fallbacks, and early termination logic.
- Applying rate limits, guardrails, and PII detection.
create_agent:
The agent loop
The core agent loop involves calling a model, letting it choose tools to execute, and then finishing when it calls no more tools: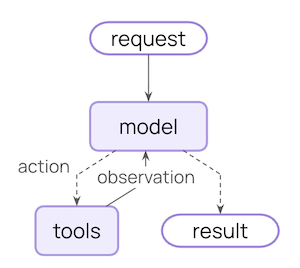
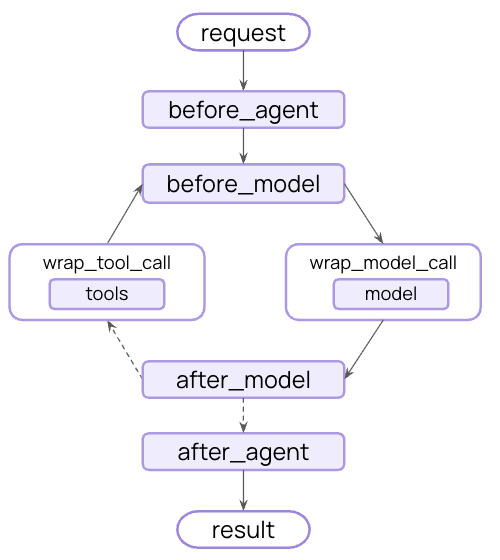
Use middleware inside a LangGraph workflow
Middleware is not a separate runtime: hooks run inside the compiled LangGraph thatcreate_agent returns. You can drop the whole agent (middleware and all) into a larger StateGraph as a node or subgraph, and every middleware hook continues to run.
Reach for this pattern when the surrounding topology is more than a standard “loop until done”: classifying input before routing to one of several agents, fanning out work in parallel, or stitching agent calls together with deterministic steps.
HumanInTheLoopMiddleware matches against each tool’s .name. In Python, @tool-decorated functions take their name from the function (so the key below is "send_email"); in TypeScript, the key matches the name you pass to tool({...}, { name }).
Additional resources
Built-in middleware
Explore built-in middleware for common use cases.
Custom middleware
Build your own middleware with hooks and decorators.
Middleware API reference
Complete API reference for middleware.
Middleware integrations
Provider-specific middleware for Anthropic, AWS, OpenAI, and more.
Testing agents
Test your agents with LangSmith.
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.