

- Add short-term memory as a part of your agent’s state to enable multi-turn conversations.
- Add long-term memory to store user-specific or application-level data across sessions.
Add short-term memory
Short-term memory (thread-level persistence) enables agents to track multi-turn conversations. To add short-term memory:from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph
checkpointer = InMemorySaver()
builder = StateGraph(...)
graph = builder.compile(checkpointer=checkpointer)
graph.invoke(
{"messages": [{"role": "user", "content": "hi! i am Bob"}]},
{"configurable": {"thread_id": "1"}},
)
Use in production
In production, use a checkpointer backed by a database:from langgraph.checkpoint.postgres import PostgresSaver
DB_URI = "postgresql://postgres:postgres@localhost:5432/postgres?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
builder = StateGraph(...)
graph = builder.compile(checkpointer=checkpointer)
Example: using Postgres checkpointer
Example: using Postgres checkpointer
pip install -U "psycopg[binary,pool]" langgraph langgraph-checkpoint-postgres
You need to call
checkpointer.setup() the first time you’re using Postgres checkpointer- Sync
- Async
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.postgres import PostgresSaver
model = init_chat_model(model="claude-haiku-4-5-20251001")
DB_URI = "postgresql://postgres:postgres@localhost:5432/postgres?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
# checkpointer.setup()
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "1"
}
}
stream = graph.stream_events(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
version="v3",
)
for snapshot in stream.values:
print(snapshot)
stream = graph.stream_events(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
version="v3",
)
for snapshot in stream.values:
print(snapshot)
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.postgres.aio import AsyncPostgresSaver
model = init_chat_model(model="claude-haiku-4-5-20251001")
DB_URI = "postgresql://postgres:postgres@localhost:5432/postgres?sslmode=disable"
async with AsyncPostgresSaver.from_conn_string(DB_URI) as checkpointer:
# await checkpointer.setup()
async def call_model(state: MessagesState):
response = await model.ainvoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "1"
}
}
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
version="v3",
)
async for message in stream.messages:
async for token in message.text:
print(token, end="", flush=True)
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
version="v3",
)
async for message in stream.messages:
async for token in message.text:
print(token, end="", flush=True)
Example: using MongoDB checkpointer
Example: using MongoDB checkpointer
pip install -U pymongo langgraph langgraph-checkpoint-mongodb
Setup
To use the MongoDB checkpointer, you will need a MongoDB cluster. Follow this guide to create a cluster if you don’t already have one.
- Sync
- Async
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.mongodb import MongoDBSaver
model = init_chat_model(model="claude-haiku-4-5-20251001")
MONGODB_URI = "localhost:27017"
with MongoDBSaver.from_conn_string(MONGODB_URI) as checkpointer:
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "1"
}
}
stream = graph.stream_events(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
version="v3",
)
for snapshot in stream.values:
print(snapshot)
stream = graph.stream_events(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
version="v3",
)
for snapshot in stream.values:
print(snapshot)
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.mongodb.aio import AsyncMongoDBSaver
model = init_chat_model(model="claude-haiku-4-5-20251001")
MONGODB_URI = "localhost:27017"
async with AsyncMongoDBSaver.from_conn_string(MONGODB_URI) as checkpointer:
async def call_model(state: MessagesState):
response = await model.ainvoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "1"
}
}
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
version="v3",
)
async for message in stream.messages:
async for token in message.text:
print(token, end="", flush=True)
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
version="v3",
)
async for message in stream.messages:
async for token in message.text:
print(token, end="", flush=True)
Example: using Redis checkpointer
Example: using Redis checkpointer
pip install -U langgraph langgraph-checkpoint-redis
You need to call
checkpointer.setup() the first time you’re using Redis checkpointer.- Sync
- Async
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.redis import RedisSaver
model = init_chat_model(model="claude-haiku-4-5-20251001")
DB_URI = "redis://localhost:6379"
with RedisSaver.from_conn_string(DB_URI) as checkpointer:
# checkpointer.setup()
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "1"
}
}
stream = graph.stream_events(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
version="v3",
)
for snapshot in stream.values:
print(snapshot)
stream = graph.stream_events(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
version="v3",
)
for snapshot in stream.values:
print(snapshot)
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.redis.aio import AsyncRedisSaver
model = init_chat_model(model="claude-haiku-4-5-20251001")
DB_URI = "redis://localhost:6379"
async with AsyncRedisSaver.from_conn_string(DB_URI) as checkpointer:
# await checkpointer.asetup()
async def call_model(state: MessagesState):
response = await model.ainvoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "1"
}
}
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
version="v3",
)
async for message in stream.messages:
async for token in message.text:
print(token, end="", flush=True)
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
version="v3",
)
async for message in stream.messages:
async for token in message.text:
print(token, end="", flush=True)
Example: using Oracle checkpointer
Example: using Oracle checkpointer
pip install -U langgraph langgraph-oracledb
Setup
To use the Oracle checkpointer, you will need an Oracle AI Database instance. A local container (for example
gvenzl/oracle-free:23-slim) or an Oracle Autonomous Database in OCI both work.You need to call
checkpointer.setup() the first time you’re using the Oracle checkpointer.- Sync
- Async
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph_oracledb.checkpoint.oracle import OracleSaver
model = init_chat_model(model="claude-haiku-4-5-20251001")
DB_URI = "user/password@localhost:1521/FREEPDB1"
with OracleSaver.from_conn_string(DB_URI) as checkpointer:
# checkpointer.setup()
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "1"
}
}
stream = graph.stream_events(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
version="v3",
)
for snapshot in stream.values:
print(snapshot)
stream = graph.stream_events(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
version="v3",
)
for snapshot in stream.values:
print(snapshot)
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph_oracledb.checkpoint.oracle import AsyncOracleSaver
model = init_chat_model(model="claude-haiku-4-5-20251001")
DB_URI = "user/password@localhost:1521/FREEPDB1"
async with AsyncOracleSaver.from_conn_string(DB_URI) as checkpointer:
# await checkpointer.setup()
async def call_model(state: MessagesState):
response = await model.ainvoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "1"
}
}
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
version="v3",
)
async for message in stream.messages:
async for token in message.text:
print(token, end="", flush=True)
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
version="v3",
)
async for message in stream.messages:
async for token in message.text:
print(token, end="", flush=True)
Use in subgraphs
If your graph contains subgraphs, you only need to provide the checkpointer when compiling the parent graph. LangGraph will automatically propagate the checkpointer to the child subgraphs.from langgraph.graph import START, StateGraph
from langgraph.checkpoint.memory import InMemorySaver
from typing import TypedDict
class State(TypedDict):
foo: str
# Subgraph
def subgraph_node_1(state: State):
return {"foo": state["foo"] + "bar"}
subgraph_builder = StateGraph(State)
subgraph_builder.add_node(subgraph_node_1)
subgraph_builder.add_edge(START, "subgraph_node_1")
subgraph = subgraph_builder.compile()
# Parent graph
builder = StateGraph(State)
builder.add_node("node_1", subgraph)
builder.add_edge(START, "node_1")
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
subgraph_builder = StateGraph(...)
subgraph = subgraph_builder.compile(checkpointer=True)
Add long-term memory
Use long-term memory to store user-specific or application-specific data across conversations.from langgraph.store.memory import InMemoryStore
from langgraph.graph import StateGraph
store = InMemoryStore()
builder = StateGraph(...)
graph = builder.compile(store=store)
Access the store inside nodes
Once you compile a graph with a store, LangGraph automatically injects the store into your node functions. The recommended way to access the store is through theRuntime object.
from dataclasses import dataclass
from langgraph.runtime import Runtime
from langgraph.graph import StateGraph, MessagesState, START
import uuid
@dataclass
class Context:
user_id: str
async def call_model(state: MessagesState, runtime: Runtime[Context]):
user_id = runtime.context.user_id
namespace = (user_id, "memories")
# Search for relevant memories
memories = await runtime.store.asearch(
namespace, query=state["messages"][-1].content, limit=3
)
info = "\n".join([d.value["data"] for d in memories])
# ... Use memories in model call
# Store a new memory
await runtime.store.aput(
namespace, str(uuid.uuid4()), {"data": "User prefers dark mode"}
)
builder = StateGraph(MessagesState, context_schema=Context)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(store=store)
# Pass context at invocation time
graph.invoke(
{"messages": [{"role": "user", "content": "hi"}]},
{"configurable": {"thread_id": "1"}},
context=Context(user_id="1"),
)
Use in production
In production, use a store backed by a database:from langgraph.store.postgres import PostgresStore
DB_URI = "postgresql://postgres:postgres@localhost:5432/postgres?sslmode=disable"
with PostgresStore.from_conn_string(DB_URI) as store:
builder = StateGraph(...)
graph = builder.compile(store=store)
Example: using Postgres store
Example: using Postgres store
pip install -U "psycopg[binary,pool]" langgraph langgraph-checkpoint-postgres
You need to call
store.setup() the first time you’re using Postgres store- Async
- Sync
from dataclasses import dataclass
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.postgres.aio import AsyncPostgresSaver
from langgraph.store.postgres.aio import AsyncPostgresStore
from langgraph.runtime import Runtime
import uuid
model = init_chat_model(model="claude-haiku-4-5-20251001")
@dataclass
class Context:
user_id: str
async def call_model(
state: MessagesState,
runtime: Runtime[Context],
):
user_id = runtime.context.user_id
namespace = ("memories", user_id)
memories = await runtime.store.asearch(namespace, query=str(state["messages"][-1].content))
info = "\n".join([d.value["data"] for d in memories])
system_msg = f"You are a helpful assistant talking to the user. User info: {info}"
# Store new memories if the user asks the model to remember
last_message = state["messages"][-1]
if "remember" in last_message.content.lower():
memory = "User name is Bob"
await runtime.store.aput(namespace, str(uuid.uuid4()), {"data": memory})
response = await model.ainvoke(
[{"role": "system", "content": system_msg}] + state["messages"]
)
return {"messages": response}
DB_URI = "postgresql://postgres:postgres@localhost:5432/postgres?sslmode=disable"
async with (
AsyncPostgresStore.from_conn_string(DB_URI) as store,
AsyncPostgresSaver.from_conn_string(DB_URI) as checkpointer,
):
# await store.setup()
# await checkpointer.setup()
builder = StateGraph(MessagesState, context_schema=Context)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(
checkpointer=checkpointer,
store=store,
)
config = {"configurable": {"thread_id": "1"}}
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "Hi! Remember: my name is Bob"}]},
config,
version="v3",
context=Context(user_id="1"),
)
async for message in stream.messages:
async for token in message.text:
print(token, end="", flush=True)
config = {"configurable": {"thread_id": "2"}}
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "what is my name?"}]},
config,
version="v3",
context=Context(user_id="1"),
)
async for message in stream.messages:
async for token in message.text:
print(token, end="", flush=True)
from dataclasses import dataclass
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.store.postgres import PostgresStore
from langgraph.runtime import Runtime
import uuid
model = init_chat_model(model="claude-haiku-4-5-20251001")
@dataclass
class Context:
user_id: str
def call_model(
state: MessagesState,
runtime: Runtime[Context],
):
user_id = runtime.context.user_id
namespace = ("memories", user_id)
memories = runtime.store.search(namespace, query=str(state["messages"][-1].content))
info = "\n".join([d.value["data"] for d in memories])
system_msg = f"You are a helpful assistant talking to the user. User info: {info}"
# Store new memories if the user asks the model to remember
last_message = state["messages"][-1]
if "remember" in last_message.content.lower():
memory = "User name is Bob"
runtime.store.put(namespace, str(uuid.uuid4()), {"data": memory})
response = model.invoke(
[{"role": "system", "content": system_msg}] + state["messages"]
)
return {"messages": response}
DB_URI = "postgresql://postgres:postgres@localhost:5432/postgres?sslmode=disable"
with (
PostgresStore.from_conn_string(DB_URI) as store,
PostgresSaver.from_conn_string(DB_URI) as checkpointer,
):
# store.setup()
# checkpointer.setup()
builder = StateGraph(MessagesState, context_schema=Context)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(
checkpointer=checkpointer,
store=store,
)
config = {"configurable": {"thread_id": "1"}}
stream = graph.stream_events(
{"messages": [{"role": "user", "content": "Hi! Remember: my name is Bob"}]},
config,
version="v3",
context=Context(user_id="1"),
)
for snapshot in stream.values:
print(snapshot)
config = {"configurable": {"thread_id": "2"}}
stream = graph.stream_events(
{"messages": [{"role": "user", "content": "what is my name?"}]},
config,
version="v3",
context=Context(user_id="1"),
)
for snapshot in stream.values:
print(snapshot)
Example: using MongoDB store
Example: using MongoDB store
Example: using Redis store
Example: using Redis store
pip install -U langgraph langgraph-checkpoint-redis
You need to call
store.setup() the first time you’re using Redis store.- Async
- Sync
from dataclasses import dataclass
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.redis.aio import AsyncRedisSaver
from langgraph.store.redis.aio import AsyncRedisStore
from langgraph.runtime import Runtime
import uuid
model = init_chat_model(model="claude-haiku-4-5-20251001")
@dataclass
class Context:
user_id: str
async def call_model(
state: MessagesState,
runtime: Runtime[Context],
):
user_id = runtime.context.user_id
namespace = ("memories", user_id)
memories = await runtime.store.asearch(namespace, query=str(state["messages"][-1].content))
info = "\n".join([d.value["data"] for d in memories])
system_msg = f"You are a helpful assistant talking to the user. User info: {info}"
# Store new memories if the user asks the model to remember
last_message = state["messages"][-1]
if "remember" in last_message.content.lower():
memory = "User name is Bob"
await runtime.store.aput(namespace, str(uuid.uuid4()), {"data": memory})
response = await model.ainvoke(
[{"role": "system", "content": system_msg}] + state["messages"]
)
return {"messages": response}
DB_URI = "redis://localhost:6379"
async with (
AsyncRedisStore.from_conn_string(DB_URI) as store,
AsyncRedisSaver.from_conn_string(DB_URI) as checkpointer,
):
# await store.setup()
# await checkpointer.asetup()
builder = StateGraph(MessagesState, context_schema=Context)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(
checkpointer=checkpointer,
store=store,
)
config = {"configurable": {"thread_id": "1"}}
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "Hi! Remember: my name is Bob"}]},
config,
version="v3",
context=Context(user_id="1"),
)
async for snapshot in stream.values:
snapshot["messages"][-1].pretty_print()
config = {"configurable": {"thread_id": "2"}}
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "what is my name?"}]},
config,
version="v3",
context=Context(user_id="1"),
)
async for snapshot in stream.values:
snapshot["messages"][-1].pretty_print()
from dataclasses import dataclass
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.redis import RedisSaver
from langgraph.store.redis import RedisStore
from langgraph.runtime import Runtime
import uuid
model = init_chat_model(model="claude-haiku-4-5-20251001")
@dataclass
class Context:
user_id: str
def call_model(
state: MessagesState,
runtime: Runtime[Context],
):
user_id = runtime.context.user_id
namespace = ("memories", user_id)
memories = runtime.store.search(namespace, query=str(state["messages"][-1].content))
info = "\n".join([d.value["data"] for d in memories])
system_msg = f"You are a helpful assistant talking to the user. User info: {info}"
# Store new memories if the user asks the model to remember
last_message = state["messages"][-1]
if "remember" in last_message.content.lower():
memory = "User name is Bob"
runtime.store.put(namespace, str(uuid.uuid4()), {"data": memory})
response = model.invoke(
[{"role": "system", "content": system_msg}] + state["messages"]
)
return {"messages": response}
DB_URI = "redis://localhost:6379"
with (
RedisStore.from_conn_string(DB_URI) as store,
RedisSaver.from_conn_string(DB_URI) as checkpointer,
):
store.setup()
checkpointer.setup()
builder = StateGraph(MessagesState, context_schema=Context)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(
checkpointer=checkpointer,
store=store,
)
config = {"configurable": {"thread_id": "1"}}
stream = graph.stream_events(
{"messages": [{"role": "user", "content": "Hi! Remember: my name is Bob"}]},
config,
version="v3",
context=Context(user_id="1"),
)
for snapshot in stream.values:
snapshot["messages"][-1].pretty_print()
config = {"configurable": {"thread_id": "2"}}
stream = graph.stream_events(
{"messages": [{"role": "user", "content": "what is my name?"}]},
config,
version="v3",
context=Context(user_id="1"),
)
for snapshot in stream.values:
snapshot["messages"][-1].pretty_print()
Example: using Oracle store
Example: using Oracle store
pip install -U langgraph langgraph-oracledb langchain-openai
Setup
To use the Oracle store, you will need an Oracle AI Database instance — the vector index used for semantic
search requires Oracle AI Vector Search.You need to call
store.setup() and checkpointer.setup() the first time you’re using the Oracle store and checkpointer.- Sync
- Async
import uuid
from langchain.chat_models import init_chat_model
from langchain.embeddings import init_embeddings
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.store.base import BaseStore
from langgraph_oracledb.checkpoint.oracle import OracleSaver
from langgraph_oracledb.store.oracle import OracleStore
model = init_chat_model(model="claude-haiku-4-5-20251001")
embeddings = init_embeddings("openai:text-embedding-3-small")
DB_URI = "user/password@localhost:1521/FREEPDB1"
with (
OracleStore.from_conn_string(
DB_URI,
index={"embed": embeddings, "dims": 1536},
) as store,
OracleSaver.from_conn_string(DB_URI) as checkpointer,
):
store.setup()
checkpointer.setup()
def call_model(
state: MessagesState,
config: RunnableConfig,
*,
store: BaseStore,
):
user_id = config["configurable"]["user_id"]
namespace = ("memories", user_id)
memories = store.search(namespace, query=str(state["messages"][-1].content))
info = "\n".join([d.value["data"] for d in memories])
system_msg = f"You are a helpful assistant talking to the user. User info: {info}"
# Store new memories if the user asks the model to remember
last_message = state["messages"][-1]
if "remember" in last_message.content.lower():
memory = "User name is Bob"
store.put(namespace, str(uuid.uuid4()), {"data": memory})
response = model.invoke(
[{"role": "system", "content": system_msg}] + state["messages"]
)
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(
checkpointer=checkpointer,
store=store,
)
config = {
"configurable": {
"thread_id": "1",
"user_id": "1",
}
}
stream = graph.stream_events(
{"messages": [{"role": "user", "content": "Hi! Remember: my name is Bob"}]},
config,
version="v3",
)
for snapshot in stream.values:
snapshot["messages"][-1].pretty_print()
config = {
"configurable": {
"thread_id": "2",
"user_id": "1",
}
}
stream = graph.stream_events(
{"messages": [{"role": "user", "content": "what is my name?"}]},
config,
version="v3",
)
for snapshot in stream.values:
snapshot["messages"][-1].pretty_print()
import uuid
from langchain.chat_models import init_chat_model
from langchain.embeddings import init_embeddings
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.store.base import BaseStore
from langgraph_oracledb.checkpoint.oracle import AsyncOracleSaver
from langgraph_oracledb.store.oracle import AsyncOracleStore
model = init_chat_model(model="claude-haiku-4-5-20251001")
embeddings = init_embeddings("openai:text-embedding-3-small")
DB_URI = "user/password@localhost:1521/FREEPDB1"
async with (
AsyncOracleStore.from_conn_string(
DB_URI,
index={"embed": embeddings, "dims": 1536},
) as store,
AsyncOracleSaver.from_conn_string(DB_URI) as checkpointer,
):
await store.setup()
await checkpointer.setup()
async def call_model(
state: MessagesState,
config: RunnableConfig,
*,
store: BaseStore,
):
user_id = config["configurable"]["user_id"]
namespace = ("memories", user_id)
memories = await store.asearch(namespace, query=str(state["messages"][-1].content))
info = "\n".join([d.value["data"] for d in memories])
system_msg = f"You are a helpful assistant talking to the user. User info: {info}"
# Store new memories if the user asks the model to remember
last_message = state["messages"][-1]
if "remember" in last_message.content.lower():
memory = "User name is Bob"
await store.aput(namespace, str(uuid.uuid4()), {"data": memory})
response = await model.ainvoke(
[{"role": "system", "content": system_msg}] + state["messages"]
)
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(
checkpointer=checkpointer,
store=store,
)
config = {
"configurable": {
"thread_id": "1",
"user_id": "1",
}
}
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "Hi! Remember: my name is Bob"}]},
config,
version="v3",
)
async for snapshot in stream.values:
snapshot["messages"][-1].pretty_print()
config = {
"configurable": {
"thread_id": "2",
"user_id": "1",
}
}
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "what is my name?"}]},
config,
version="v3",
)
async for snapshot in stream.values:
snapshot["messages"][-1].pretty_print()
Use semantic search
Enable semantic search in your graph’s memory store to let graph agents search for items in the store by semantic similarity.from langchain.embeddings import init_embeddings
from langgraph.store.memory import InMemoryStore
# Create store with semantic search enabled
embeddings = init_embeddings("openai:text-embedding-3-small")
store = InMemoryStore(
index={
"embed": embeddings,
"dims": 1536,
}
)
store.put(("user_123", "memories"), "1", {"text": "I love pizza"})
store.put(("user_123", "memories"), "2", {"text": "I am a plumber"})
items = store.search(
("user_123", "memories"), query="I'm hungry", limit=1
)
Long-term memory with semantic search
Long-term memory with semantic search
from langchain.embeddings import init_embeddings
from langchain.chat_models import init_chat_model
from langgraph.store.memory import InMemoryStore
from langgraph.graph import START, MessagesState, StateGraph
from langgraph.runtime import Runtime
model = init_chat_model("gpt-5.4-mini")
# Create store with semantic search enabled
embeddings = init_embeddings("openai:text-embedding-3-small")
store = InMemoryStore(
index={
"embed": embeddings,
"dims": 1536,
}
)
store.put(("user_123", "memories"), "1", {"text": "I love pizza"})
store.put(("user_123", "memories"), "2", {"text": "I am a plumber"})
async def chat(state: MessagesState, runtime: Runtime):
# Search based on user's last message
items = await runtime.store.asearch(
("user_123", "memories"), query=state["messages"][-1].content, limit=2
)
memories = "\n".join(item.value["text"] for item in items)
memories = f"## Memories of user\n{memories}" if memories else ""
response = await model.ainvoke(
[
{"role": "system", "content": f"You are a helpful assistant.\n{memories}"},
*state["messages"],
]
)
return {"messages": [response]}
builder = StateGraph(MessagesState)
builder.add_node(chat)
builder.add_edge(START, "chat")
graph = builder.compile(store=store)
stream = await graph.astream_events(
{"messages": [{"role": "user", "content": "I'm hungry"}]},
version="v3",
)
async for message in stream.messages:
async for token in message.text:
print(token, end="", flush=True)
Manage short-term memory
With short-term memory enabled, long conversations can exceed the LLM’s context window. Common solutions are:- Trim messages: Remove first or last N messages (before calling LLM)
- Delete messages from LangGraph state permanently
- Summarize messages: Summarize earlier messages in the history and replace them with a summary
- Manage checkpoints to store and retrieve message history
- Custom strategies (e.g., message filtering, etc.)
Trim messages
Most LLMs have a maximum supported context window (denominated in tokens). One way to decide when to truncate messages is to count the tokens in the message history and truncate whenever it approaches that limit. If you’re using LangChain, you can use the trim messages utility and specify the number of tokens to keep from the list, as well as thestrategy (e.g., keep the last max_tokens) to use for handling the boundary.
To trim message history, use the trim_messages function:
from langchain_core.messages.utils import (
trim_messages,
count_tokens_approximately
)
def call_model(state: MessagesState):
messages = trim_messages(
state["messages"],
strategy="last",
token_counter=count_tokens_approximately,
max_tokens=128,
start_on="human",
end_on=("human", "tool"),
)
response = model.invoke(messages)
return {"messages": [response]}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
...
Full example: trim messages
Full example: trim messages
from langchain_core.messages.utils import (
trim_messages,
count_tokens_approximately
)
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, START, MessagesState
model = init_chat_model("claude-sonnet-4-6")
summarization_model = model.bind(max_tokens=128)
def call_model(state: MessagesState):
messages = trim_messages(
state["messages"],
strategy="last",
token_counter=count_tokens_approximately,
max_tokens=128,
start_on="human",
end_on=("human", "tool"),
)
response = model.invoke(messages)
return {"messages": [response]}
checkpointer = InMemorySaver()
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {"configurable": {"thread_id": "1"}}
graph.invoke({"messages": "hi, my name is bob"}, config)
graph.invoke({"messages": "write a short poem about cats"}, config)
graph.invoke({"messages": "now do the same but for dogs"}, config)
final_response = graph.invoke({"messages": "what's my name?"}, config)
final_response["messages"][-1].pretty_print()
================================== Ai Message ==================================
Your name is Bob, as you mentioned when you first introduced yourself.
Delete messages
You can delete messages from the graph state to manage the message history. This is useful when you want to remove specific messages or clear the entire message history. To delete messages from the graph state, you can use theRemoveMessage. For RemoveMessage to work, you need to use a state key with add_messages reducer, like MessagesState.
To remove specific messages:
from langchain.messages import RemoveMessage
def delete_messages(state):
messages = state["messages"]
if len(messages) > 2:
# remove the earliest two messages
return {"messages": [RemoveMessage(id=m.id) for m in messages[:2]]}
from langgraph.graph.message import REMOVE_ALL_MESSAGES
def delete_messages(state):
return {"messages": [RemoveMessage(id=REMOVE_ALL_MESSAGES)]}
When deleting messages, make sure that the resulting message history is valid. Check the limitations of the LLM provider you’re using. For example:
- Some providers expect message history to start with a
usermessage - Most providers require
assistantmessages with tool calls to be followed by correspondingtoolresult messages.
Full example: delete messages
Full example: delete messages
from langchain.messages import RemoveMessage
def delete_messages(state):
messages = state["messages"]
if len(messages) > 2:
# remove the earliest two messages
return {"messages": [RemoveMessage(id=m.id) for m in messages[:2]]}
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_sequence([call_model, delete_messages])
builder.add_edge(START, "call_model")
checkpointer = InMemorySaver()
app = builder.compile(checkpointer=checkpointer)
stream = app.stream_events(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
version="v3"
)
for snapshot in stream.values:
print([(message.type, message.content) for message in snapshot["messages"]])
stream = app.stream_events(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
version="v3"
)
for snapshot in stream.values:
print([(message.type, message.content) for message in snapshot["messages"]])
[('human', "hi! I'm bob")]
[('human', "hi! I'm bob"), ('ai', 'Hi Bob! How are you doing today? Is there anything I can help you with?')]
[('human', "hi! I'm bob"), ('ai', 'Hi Bob! How are you doing today? Is there anything I can help you with?'), ('human', "what's my name?")]
[('human', "hi! I'm bob"), ('ai', 'Hi Bob! How are you doing today? Is there anything I can help you with?'), ('human', "what's my name?"), ('ai', 'Your name is Bob.')]
[('human', "what's my name?"), ('ai', 'Your name is Bob.')]
Summarize messages
The problem with trimming or removing messages, as shown above, is that you may lose information from culling of the message queue. Because of this, some applications benefit from a more sophisticated approach of summarizing the message history using a chat model.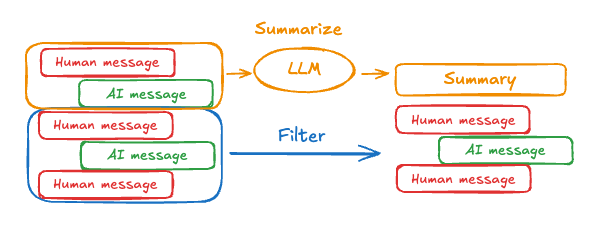
MessagesState to include a summary key:
from langgraph.graph import MessagesState
class State(MessagesState):
summary: str
summarize_conversation node can be called after some number of messages have accumulated in the messages state key.
def summarize_conversation(state: State):
# First, we get any existing summary
summary = state.get("summary", "")
# Create our summarization prompt
if summary:
# A summary already exists
summary_message = (
f"This is a summary of the conversation to date: {summary}\n\n"
"Extend the summary by taking into account the new messages above:"
)
else:
summary_message = "Create a summary of the conversation above:"
# Add prompt to our history
messages = state["messages"] + [HumanMessage(content=summary_message)]
response = model.invoke(messages)
# Delete all but the 2 most recent messages
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]
return {"summary": response.content, "messages": delete_messages}
Full example: summarize messages
Full example: summarize messages
from typing import Any, TypedDict
from langchain.chat_models import init_chat_model
from langchain.messages import AnyMessage
from langchain_core.messages.utils import count_tokens_approximately
from langgraph.graph import StateGraph, START, MessagesState
from langgraph.checkpoint.memory import InMemorySaver
from langmem.short_term import SummarizationNode, RunningSummary
model = init_chat_model("claude-sonnet-4-6")
summarization_model = model.bind(max_tokens=128)
class State(MessagesState):
context: dict[str, RunningSummary]
class LLMInputState(TypedDict):
summarized_messages: list[AnyMessage]
context: dict[str, RunningSummary]
summarization_node = SummarizationNode(
token_counter=count_tokens_approximately,
model=summarization_model,
max_tokens=256,
max_tokens_before_summary=256,
max_summary_tokens=128,
)
def call_model(state: LLMInputState):
response = model.invoke(state["summarized_messages"])
return {"messages": [response]}
checkpointer = InMemorySaver()
builder = StateGraph(State)
builder.add_node(call_model)
builder.add_node("summarize", summarization_node)
builder.add_edge(START, "summarize")
builder.add_edge("summarize", "call_model")
graph = builder.compile(checkpointer=checkpointer)
# Invoke the graph
config = {"configurable": {"thread_id": "1"}}
graph.invoke({"messages": "hi, my name is bob"}, config)
graph.invoke({"messages": "write a short poem about cats"}, config)
graph.invoke({"messages": "now do the same but for dogs"}, config)
final_response = graph.invoke({"messages": "what's my name?"}, config)
final_response["messages"][-1].pretty_print()
print("\nSummary:", final_response["context"]["running_summary"].summary)
- We will keep track of our running summary in the
contextfield
SummarizationNode).- Define private state that will be used only for filtering
call_model node.- We’re passing a private input state here to isolate the messages returned by the summarization node
================================== Ai Message ==================================
From our conversation, I can see that you introduced yourself as Bob. That's the name you shared with me when we began talking.
Summary: In this conversation, I was introduced to Bob, who then asked me to write a poem about cats. I composed a poem titled "The Mystery of Cats" that captured cats' graceful movements, independent nature, and their special relationship with humans. Bob then requested a similar poem about dogs, so I wrote "The Joy of Dogs," which highlighted dogs' loyalty, enthusiasm, and loving companionship. Both poems were written in a similar style but emphasized the distinct characteristics that make each pet special.
Manage checkpoints
You can view and delete the information stored by the checkpointer.View thread state
- Graph/Functional API
- Checkpointer API
config = {
"configurable": {
"thread_id": "1",
# optionally provide an ID for a specific checkpoint,
# otherwise the latest checkpoint is shown
# "checkpoint_id": "1f029ca3-1f5b-6704-8004-820c16b69a5a" #
}
}
graph.get_state(config)
StateSnapshot(
values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today?), HumanMessage(content="what's my name?"), AIMessage(content='Your name is Bob.')]}, next=(),
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1f5b-6704-8004-820c16b69a5a'}},
metadata={
'source': 'loop',
'writes': {'call_model': {'messages': AIMessage(content='Your name is Bob.')}},
'step': 4,
'parents': {},
'thread_id': '1'
},
created_at='2025-05-05T16:01:24.680462+00:00',
parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1790-6b0a-8003-baf965b6a38f'}},
tasks=(),
interrupts=()
)
config = {
"configurable": {
"thread_id": "1",
# optionally provide an ID for a specific checkpoint,
# otherwise the latest checkpoint is shown
# "checkpoint_id": "1f029ca3-1f5b-6704-8004-820c16b69a5a" #
}
}
checkpointer.get_tuple(config)
CheckpointTuple(
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1f5b-6704-8004-820c16b69a5a'}},
checkpoint={
'v': 3,
'ts': '2025-05-05T16:01:24.680462+00:00',
'id': '1f029ca3-1f5b-6704-8004-820c16b69a5a',
'channel_versions': {'__start__': '00000000000000000000000000000005.0.5290678567601859', 'messages': '00000000000000000000000000000006.0.3205149138784782', 'branch:to:call_model': '00000000000000000000000000000006.0.14611156755133758'}, 'versions_seen': {'__input__': {}, '__start__': {'__start__': '00000000000000000000000000000004.0.5736472536395331'}, 'call_model': {'branch:to:call_model': '00000000000000000000000000000005.0.1410174088651449'}},
'channel_values': {'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today?), HumanMessage(content="what's my name?"), AIMessage(content='Your name is Bob.')]},
},
metadata={
'source': 'loop',
'writes': {'call_model': {'messages': AIMessage(content='Your name is Bob.')}},
'step': 4,
'parents': {},
'thread_id': '1'
},
parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1790-6b0a-8003-baf965b6a38f'}},
pending_writes=[]
)
View the history of the thread
- Graph/Functional API
- Checkpointer API
config = {
"configurable": {
"thread_id": "1"
}
}
list(graph.get_state_history(config))
[
StateSnapshot(
values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?'), HumanMessage(content="what's my name?"), AIMessage(content='Your name is Bob.')]},
next=(),
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1f5b-6704-8004-820c16b69a5a'}},
metadata={'source': 'loop', 'writes': {'call_model': {'messages': AIMessage(content='Your name is Bob.')}}, 'step': 4, 'parents': {}, 'thread_id': '1'},
created_at='2025-05-05T16:01:24.680462+00:00',
parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1790-6b0a-8003-baf965b6a38f'}},
tasks=(),
interrupts=()
),
StateSnapshot(
values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?'), HumanMessage(content="what's my name?")]},
next=('call_model',),
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1790-6b0a-8003-baf965b6a38f'}},
metadata={'source': 'loop', 'writes': None, 'step': 3, 'parents': {}, 'thread_id': '1'},
created_at='2025-05-05T16:01:23.863421+00:00',
parent_config={...}
tasks=(PregelTask(id='8ab4155e-6b15-b885-9ce5-bed69a2c305c', name='call_model', path=('__pregel_pull', 'call_model'), error=None, interrupts=(), state=None, result={'messages': AIMessage(content='Your name is Bob.')}),),
interrupts=()
),
StateSnapshot(
values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')]},
next=('__start__',),
config={...},
metadata={'source': 'input', 'writes': {'__start__': {'messages': [{'role': 'user', 'content': "what's my name?"}]}}, 'step': 2, 'parents': {}, 'thread_id': '1'},
created_at='2025-05-05T16:01:23.863173+00:00',
parent_config={...}
tasks=(PregelTask(id='24ba39d6-6db1-4c9b-f4c5-682aeaf38dcd', name='__start__', path=('__pregel_pull', '__start__'), error=None, interrupts=(), state=None, result={'messages': [{'role': 'user', 'content': "what's my name?"}]}),),
interrupts=()
),
StateSnapshot(
values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')]},
next=(),
config={...},
metadata={'source': 'loop', 'writes': {'call_model': {'messages': AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')}}, 'step': 1, 'parents': {}, 'thread_id': '1'},
created_at='2025-05-05T16:01:23.862295+00:00',
parent_config={...}
tasks=(),
interrupts=()
),
StateSnapshot(
values={'messages': [HumanMessage(content="hi! I'm bob")]},
next=('call_model',),
config={...},
metadata={'source': 'loop', 'writes': None, 'step': 0, 'parents': {}, 'thread_id': '1'},
created_at='2025-05-05T16:01:22.278960+00:00',
parent_config={...}
tasks=(PregelTask(id='8cbd75e0-3720-b056-04f7-71ac805140a0', name='call_model', path=('__pregel_pull', 'call_model'), error=None, interrupts=(), state=None, result={'messages': AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')}),),
interrupts=()
),
StateSnapshot(
values={'messages': []},
next=('__start__',),
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-0870-6ce2-bfff-1f3f14c3e565'}},
metadata={'source': 'input', 'writes': {'__start__': {'messages': [{'role': 'user', 'content': "hi! I'm bob"}]}}, 'step': -1, 'parents': {}, 'thread_id': '1'},
created_at='2025-05-05T16:01:22.277497+00:00',
parent_config=None,
tasks=(PregelTask(id='d458367b-8265-812c-18e2-33001d199ce6', name='__start__', path=('__pregel_pull', '__start__'), error=None, interrupts=(), state=None, result={'messages': [{'role': 'user', 'content': "hi! I'm bob"}]}),),
interrupts=()
)
]
config = {
"configurable": {
"thread_id": "1"
}
}
list(checkpointer.list(config))
[
CheckpointTuple(
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1f5b-6704-8004-820c16b69a5a'}},
checkpoint={
'v': 3,
'ts': '2025-05-05T16:01:24.680462+00:00',
'id': '1f029ca3-1f5b-6704-8004-820c16b69a5a',
'channel_versions': {'__start__': '00000000000000000000000000000005.0.5290678567601859', 'messages': '00000000000000000000000000000006.0.3205149138784782', 'branch:to:call_model': '00000000000000000000000000000006.0.14611156755133758'},
'versions_seen': {'__input__': {}, '__start__': {'__start__': '00000000000000000000000000000004.0.5736472536395331'}, 'call_model': {'branch:to:call_model': '00000000000000000000000000000005.0.1410174088651449'}},
'channel_values': {'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?'), HumanMessage(content="what's my name?"), AIMessage(content='Your name is Bob.')]},
},
metadata={'source': 'loop', 'writes': {'call_model': {'messages': AIMessage(content='Your name is Bob.')}}, 'step': 4, 'parents': {}, 'thread_id': '1'},
parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1790-6b0a-8003-baf965b6a38f'}},
pending_writes=[]
),
CheckpointTuple(
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1790-6b0a-8003-baf965b6a38f'}},
checkpoint={
'v': 3,
'ts': '2025-05-05T16:01:23.863421+00:00',
'id': '1f029ca3-1790-6b0a-8003-baf965b6a38f',
'channel_versions': {'__start__': '00000000000000000000000000000005.0.5290678567601859', 'messages': '00000000000000000000000000000006.0.3205149138784782', 'branch:to:call_model': '00000000000000000000000000000006.0.14611156755133758'},
'versions_seen': {'__input__': {}, '__start__': {'__start__': '00000000000000000000000000000004.0.5736472536395331'}, 'call_model': {'branch:to:call_model': '00000000000000000000000000000005.0.1410174088651449'}},
'channel_values': {'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?'), HumanMessage(content="what's my name?")], 'branch:to:call_model': None}
},
metadata={'source': 'loop', 'writes': None, 'step': 3, 'parents': {}, 'thread_id': '1'},
parent_config={...},
pending_writes=[('8ab4155e-6b15-b885-9ce5-bed69a2c305c', 'messages', AIMessage(content='Your name is Bob.'))]
),
CheckpointTuple(
config={...},
checkpoint={
'v': 3,
'ts': '2025-05-05T16:01:23.863173+00:00',
'id': '1f029ca3-1790-616e-8002-9e021694a0cd',
'channel_versions': {'__start__': '00000000000000000000000000000004.0.5736472536395331', 'messages': '00000000000000000000000000000003.0.7056767754077798', 'branch:to:call_model': '00000000000000000000000000000003.0.22059023329132854'},
'versions_seen': {'__input__': {}, '__start__': {'__start__': '00000000000000000000000000000001.0.7040775356287469'}, 'call_model': {'branch:to:call_model': '00000000000000000000000000000002.0.9300422176788571'}},
'channel_values': {'__start__': {'messages': [{'role': 'user', 'content': "what's my name?"}]}, 'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')]}
},
metadata={'source': 'input', 'writes': {'__start__': {'messages': [{'role': 'user', 'content': "what's my name?"}]}}, 'step': 2, 'parents': {}, 'thread_id': '1'},
parent_config={...},
pending_writes=[('24ba39d6-6db1-4c9b-f4c5-682aeaf38dcd', 'messages', [{'role': 'user', 'content': "what's my name?"}]), ('24ba39d6-6db1-4c9b-f4c5-682aeaf38dcd', 'branch:to:call_model', None)]
),
CheckpointTuple(
config={...},
checkpoint={
'v': 3,
'ts': '2025-05-05T16:01:23.862295+00:00',
'id': '1f029ca3-178d-6f54-8001-d7b180db0c89',
'channel_versions': {'__start__': '00000000000000000000000000000002.0.18673090920108737', 'messages': '00000000000000000000000000000003.0.7056767754077798', 'branch:to:call_model': '00000000000000000000000000000003.0.22059023329132854'},
'versions_seen': {'__input__': {}, '__start__': {'__start__': '00000000000000000000000000000001.0.7040775356287469'}, 'call_model': {'branch:to:call_model': '00000000000000000000000000000002.0.9300422176788571'}},
'channel_values': {'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')]}
},
metadata={'source': 'loop', 'writes': {'call_model': {'messages': AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')}}, 'step': 1, 'parents': {}, 'thread_id': '1'},
parent_config={...},
pending_writes=[]
),
CheckpointTuple(
config={...},
checkpoint={
'v': 3,
'ts': '2025-05-05T16:01:22.278960+00:00',
'id': '1f029ca3-0874-6612-8000-339f2abc83b1',
'channel_versions': {'__start__': '00000000000000000000000000000002.0.18673090920108737', 'messages': '00000000000000000000000000000002.0.30296526818059655', 'branch:to:call_model': '00000000000000000000000000000002.0.9300422176788571'},
'versions_seen': {'__input__': {}, '__start__': {'__start__': '00000000000000000000000000000001.0.7040775356287469'}},
'channel_values': {'messages': [HumanMessage(content="hi! I'm bob")], 'branch:to:call_model': None}
},
metadata={'source': 'loop', 'writes': None, 'step': 0, 'parents': {}, 'thread_id': '1'},
parent_config={...},
pending_writes=[('8cbd75e0-3720-b056-04f7-71ac805140a0', 'messages', AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?'))]
),
CheckpointTuple(
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-0870-6ce2-bfff-1f3f14c3e565'}},
checkpoint={
'v': 3,
'ts': '2025-05-05T16:01:22.277497+00:00',
'id': '1f029ca3-0870-6ce2-bfff-1f3f14c3e565',
'channel_versions': {'__start__': '00000000000000000000000000000001.0.7040775356287469'},
'versions_seen': {'__input__': {}},
'channel_values': {'__start__': {'messages': [{'role': 'user', 'content': "hi! I'm bob"}]}}
},
metadata={'source': 'input', 'writes': {'__start__': {'messages': [{'role': 'user', 'content': "hi! I'm bob"}]}}, 'step': -1, 'parents': {}, 'thread_id': '1'},
parent_config=None,
pending_writes=[('d458367b-8265-812c-18e2-33001d199ce6', 'messages', [{'role': 'user', 'content': "hi! I'm bob"}]), ('d458367b-8265-812c-18e2-33001d199ce6', 'branch:to:call_model', None)]
)
]
Delete all checkpoints for a thread
thread_id = "1"
checkpointer.delete_thread(thread_id)
Database management
If you are using any database-backed persistence implementation (such as Postgres, Redis, or Oracle) to store short and/or long-term memory, you will need to run migrations to set up the required schema before you can use it with your database. By convention, most database-specific libraries define asetup() method on the checkpointer or store instance that runs the required migrations. However, you should check with your specific implementation of BaseCheckpointSaver or BaseStore to confirm the exact method name and usage.
We recommend running migrations as a dedicated deployment step, or you can ensure they’re run as part of server startup.
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.