

interrupt() function at any point in your graph nodes. The function accepts any JSON-serializable value which is surfaced to the caller. When you’re ready to continue, you resume execution by re-invoking the graph using Command, which then becomes the return value of the interrupt() call from inside the node.
Unlike static breakpoints (which pause before or after specific nodes), interrupts are dynamic: they can be placed anywhere in your code and can be conditional based on your application logic.
- Checkpointing keeps your place: the checkpointer writes the exact graph state so you can resume later, even when in an error state.
thread_idis your pointer: setconfig={"configurable": {"thread_id": ...}}to tell the checkpointer which state to load.- Interrupt payloads surface via
stream.interrupts: when using event streaming (graph.stream_events(..., version="v3")), the values you pass tointerrupt()appear onstream.interrupts, andstream.interruptedisTruewhen the run pauses for input.
thread_id you choose is effectively your persistent cursor. Reusing it resumes the same checkpoint; using a new value starts a brand-new thread with an empty state.
Pause using interrupt
The interrupt function pauses graph execution and returns a value to the caller. When you call interrupt within a node, LangGraph saves the current graph state and waits for you to resume execution with input.
To use interrupt, you need:
- A checkpointer to persist the graph state (use a durable checkpointer in production)
- A thread ID in your config so the runtime knows which state to resume from
- To call
interrupt()where you want to pause (payload must be JSON-serializable)
interrupt, here’s what happens:
-
Graph execution gets suspended at the exact point where
interruptis called - State is saved using the checkpointer so execution can be resumed later, In production, this should be a persistent checkpointer (e.g. backed by a database)
-
Value is returned to the caller on
stream.interruptswhen using event streaming (graph.stream_events(..., version="v3")), or under__interrupt__with the defaultinvoke()API; it can be any JSON-serializable value (string, object, array, etc.) - Graph waits indefinitely until you resume execution with a response
-
Response is passed back into the node when you resume, becoming the return value of the
interrupt()call
Resuming interrupts
After an interrupt pauses execution, you resume the graph by invoking it again with aCommand that contains the resume value. The resume value is passed back to the interrupt call, allowing the node to continue execution with the external input.
The recommended way to drive a graph that may interrupt is event streaming — it surfaces interrupts via stream.interrupts and stream.interrupted, and exposes the final state through stream.output.
The default
graph.invoke(...) API still works and surfaces interrupts under result["__interrupt__"]. Use it when you don’t need streamed projections; otherwise prefer graph.stream_events(..., version="v3").- You must use the same thread ID when resuming that was used when the interrupt occurred
- The value passed to
Command(resume=...)becomes the return value of theinterruptcall - The node restarts from the beginning of the node where the
interruptwas called when resumed, so any code before theinterruptruns again - You can pass any JSON-serializable value as the resume value
Common patterns
The key thing that interrupts unlock is the ability to pause execution and wait for external input. This is useful for a variety of use cases, including:- Approval workflows: Pause before executing critical actions (API calls, database changes, financial transactions)
- Handling multiple interrupts: Pair interrupt IDs with resume values when resuming multiple interrupts in a single invocation
- Review and edit: Let humans review and modify LLM outputs or tool calls before continuing
- Interrupting tool calls: Pause before executing tool calls to review and edit the tool call before execution
- Validating human input: Pause before proceeding to the next step to validate human input
Stream with human-in-the-loop (HITL) interrupts
When building interactive agents with human-in-the-loop workflows, you can use event streaming to consume message chunks and state snapshots concurrently while handling interrupts. Use the typed projections returned bygraph.stream_events(..., version="v3") in a loop until the run finishes:
- Stream AI responses token-by-token via
stream.messages - Observe per-step state snapshots via
stream.values - Detect interrupts via
stream.interruptedand read their payloads fromstream.interrupts - Resume execution by calling
stream_eventsagain withCommand(resume=...)and repeat untilstream.interruptedis false
stream.messages: Chat-model output as content blocks; iterate eachmessage.textfor token deltas. For nested subgraphs, read message chunks fromstream.subgraphs[*].messages.stream.values: Full state snapshots after each stepstream.interrupted/stream.interrupts: After each run, check whether the graph paused; read payloads fromstream.interruptsCommand(resume=...): Pass as the nextstream_eventsinput to resume; loop until the run completes without interrupting
Handling multiple interrupts
When parallel branches interrupt simultaneously (for example, fan-out to multiple nodes that each callinterrupt()), you may need to resume multiple interrupts in a single invocation.
When resuming multiple interrupts with a single invocation, map each interrupt ID to its resume value.
This ensures each response is paired with the correct interrupt at runtime.
Approve or reject
One of the most common uses of interrupts is to pause before a critical action and ask for approval. For example, you might want to ask a human to approve an API call, a database change, or any other important decision.True to approve or False to reject:
Full example
Full example
Review and edit state
Sometimes you want to let a human review and edit part of the graph state before continuing. This is useful for correcting LLMs, adding missing information, or making adjustments.Full example
Full example
Interrupts in tools
You can also place interrupts directly inside tool functions. This makes the tool itself pause for approval whenever it’s called, and allows for human review and editing of the tool call before it is executed. First, define a tool that usesinterrupt:
Full example
Full example
Validating human input
Sometimes you need to validate input from humans and re-prompt if the value is invalid. The recommended approach is to callinterrupt() once per node invocation, return from the node with the error message stored in state, and use a conditional edge to loop back to the node until a valid value is provided.
The correct pattern:
- Store the re-prompt question in state (e.g.
pending_question). - In the node, call
interrupt()exactly once, passing the current question from state. - If the answer is invalid, return the updated
pending_questionso the next invocation re-prompts. - Use
add_conditional_edgesto route back to the node until a valid value is collected.
get_age_node exactly once, runs the interrupt() call once, and exits. When the answer is invalid, the conditional edge loops back and the next interrupt re-prompts with the updated question. No code runs more than once per resume.
Full example
Full example
Rules of interrupts
When you callinterrupt within a node, LangGraph suspends execution by raising an exception that signals the runtime to pause. This exception propagates up through the call stack and is caught by the runtime, which notifies the graph to save the current state and wait for external input.
When execution resumes (after you provide the requested input), the runtime restarts the entire node from the beginning—it does not resume from the exact line where interrupt was called. This means any code that ran before the interrupt will execute again. Because of this, there’s a few important rules to follow when working with interrupts to ensure they behave as expected.
Do not wrap interrupt calls in try/except
The way that interrupt pauses execution at the point of the call is by throwing a special exception. If you wrap the interrupt call in a try/except block, you will catch this exception and the interrupt will not be passed back to the graph.
- ✅ Separate
interruptcalls from error-prone code - ✅ Use specific exception types in try/except blocks
- 🔴 Do not wrap
interruptcalls in bare try/except blocks
Do not reorder interrupt calls within a node
It’s common to use multiple interrupts in a single node, however this can lead to unexpected behavior if not handled carefully.
When a node contains multiple interrupt calls, LangGraph keeps a list of resume values specific to the task executing the node. Whenever execution resumes, it starts at the beginning of the node. For each interrupt encountered, LangGraph checks if a matching value exists in the task’s resume list. Matching is strictly index-based, so the order of interrupt calls within the node is important.
- ✅ Keep
interruptcalls consistent across node executions
- 🔴 Do not conditionally skip
interruptcalls within a node - 🔴 Do not loop
interruptcalls using logic that isn’t deterministic across executions, includingwhile Truevalidation loops. Use a conditional edge instead (see Validating human input)
Do not return complex values in interrupt calls
Depending on which checkpointer is used, complex values may not be serializable (e.g. you can’t serialize a function). To make your graphs adaptable to any deployment, it’s best practice to only use values that can be reasonably serialized.
- ✅ Pass simple, JSON-serializable types to
interrupt - ✅ Pass dictionaries/objects with simple values
- 🔴 Do not pass functions, class instances, or other complex objects to
interrupt
Side effects called before interrupt must be idempotent
Because interrupts work by re-running the nodes they were called from, side effects called before interrupt should (ideally) be idempotent. For context, idempotency means that the same operation can be applied multiple times without changing the result beyond the initial execution.
As an example, you might have an API call to update a record inside of a node. If interrupt is called after that call is made, it will be re-run multiple times when the node is resumed, potentially overwriting the initial update or creating duplicate records.
- ✅ Use idempotent operations before
interrupt - ✅ Place side effects after
interruptcalls - ✅ Separate side effects into separate nodes when possible
- 🔴 Do not perform non-idempotent operations before
interrupt - 🔴 Do not create new records without checking if they exist
Using with subgraphs called as functions
When invoking a subgraph within a node, the parent graph will resume execution from the beginning of the node where the subgraph was invoked and theinterrupt was triggered. Similarly, the subgraph will also resume from the beginning of the node where interrupt was called.
Debugging with interrupts
To debug and test a graph, you can use static interrupts as breakpoints to step through the graph execution one node at a time. Static interrupts are triggered at defined points either before or after a node executes. You can set these by specifyinginterrupt_before and interrupt_after when compiling the graph.
Static interrupts are not recommended for human-in-the-loop workflows. Use the
interrupt function instead.- At compile time
- At run time
- The breakpoints are set during
compiletime. interrupt_beforespecifies the nodes where execution should pause before the node is executed.interrupt_afterspecifies the nodes where execution should pause after the node is executed.- A checkpointer is required to enable breakpoints.
- The graph is run until the first breakpoint is hit.
- The graph is resumed by passing in
Nonefor the input. This will run the graph until the next breakpoint is hit.
Using LangSmith Studio
You can use LangSmith Studio to set static interrupts in your graph in the UI before running the graph. You can also use the UI to inspect the graph state at any point in the execution.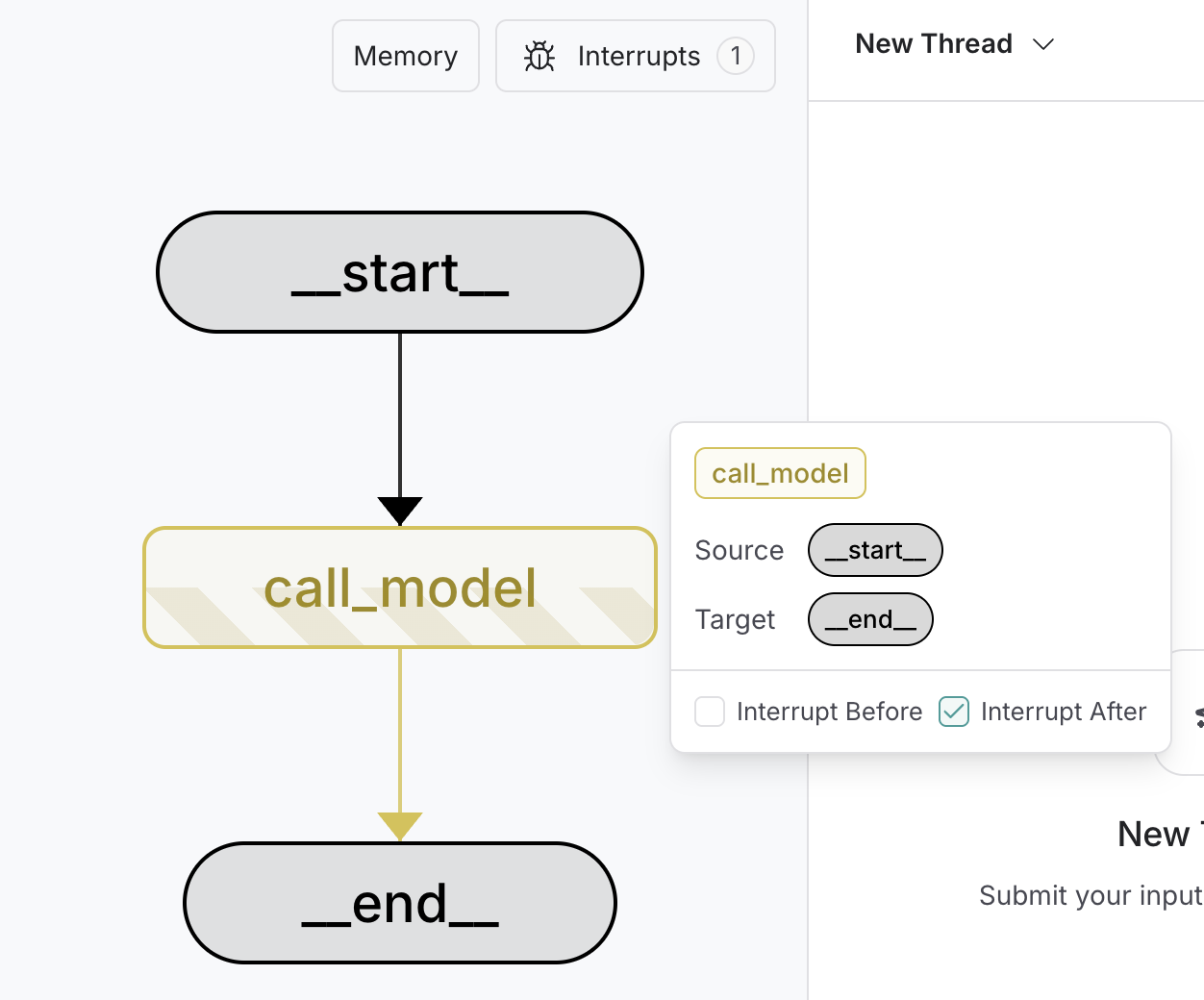
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.