

- Versioning datasets to track changes over time.
- Filtering and splitting datasets for evaluation.
- Sharing datasets publicly.
- Exporting datasets in various formats.
Version a dataset
In LangSmith, datasets are versioned. This means that every time you add, update, or delete examples in your dataset, a new version of the dataset is created.Create a new version of a dataset
Any time you add, update, or delete examples in your dataset, a new version of your dataset is created. This allows you to track changes to your dataset over time and understand how your dataset has evolved. By default, the version is defined by the timestamp of the change. When you click on a particular version of a dataset (by timestamp) in the Examples tab, you will find the state of the dataset at that point in time.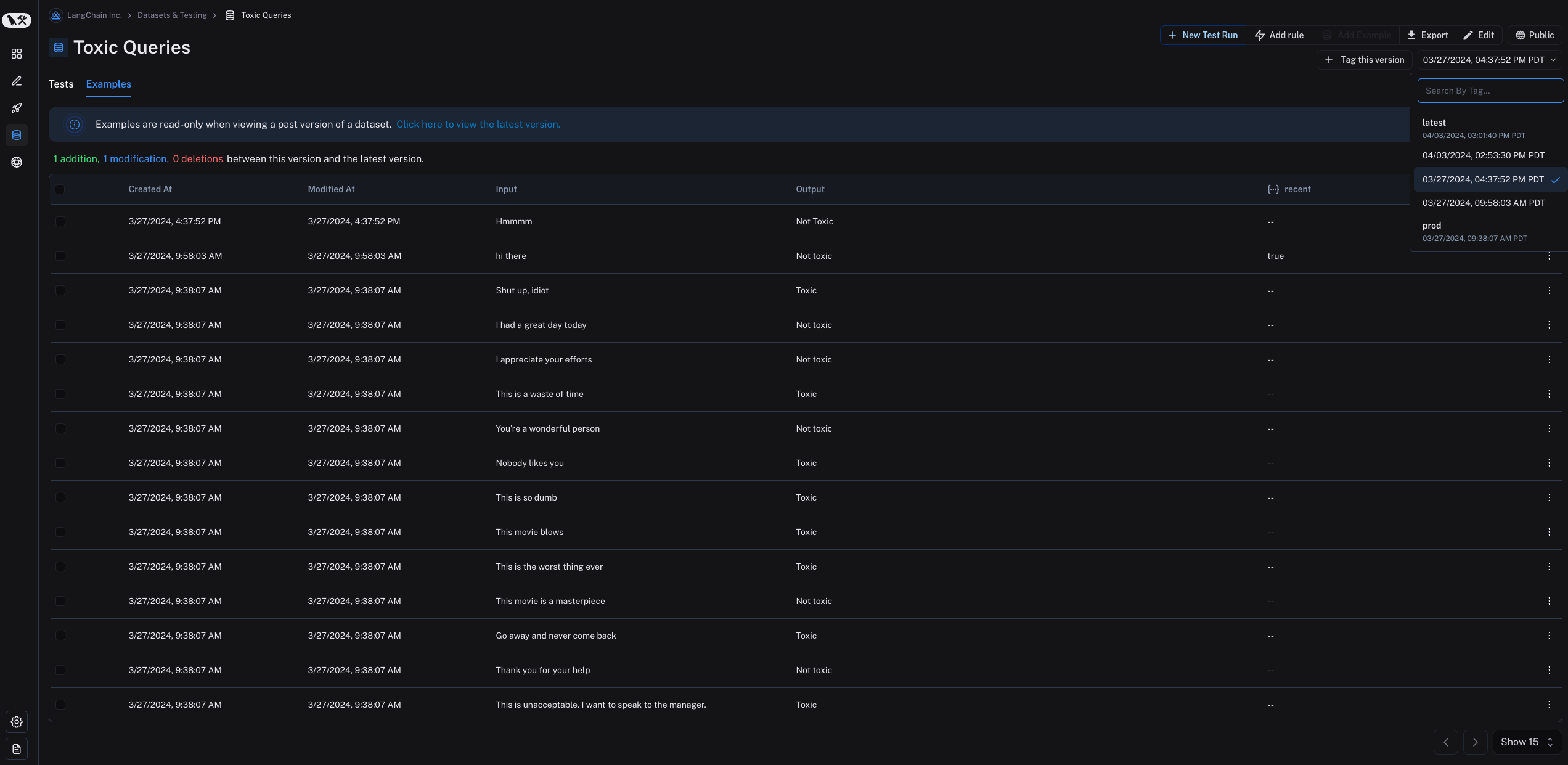
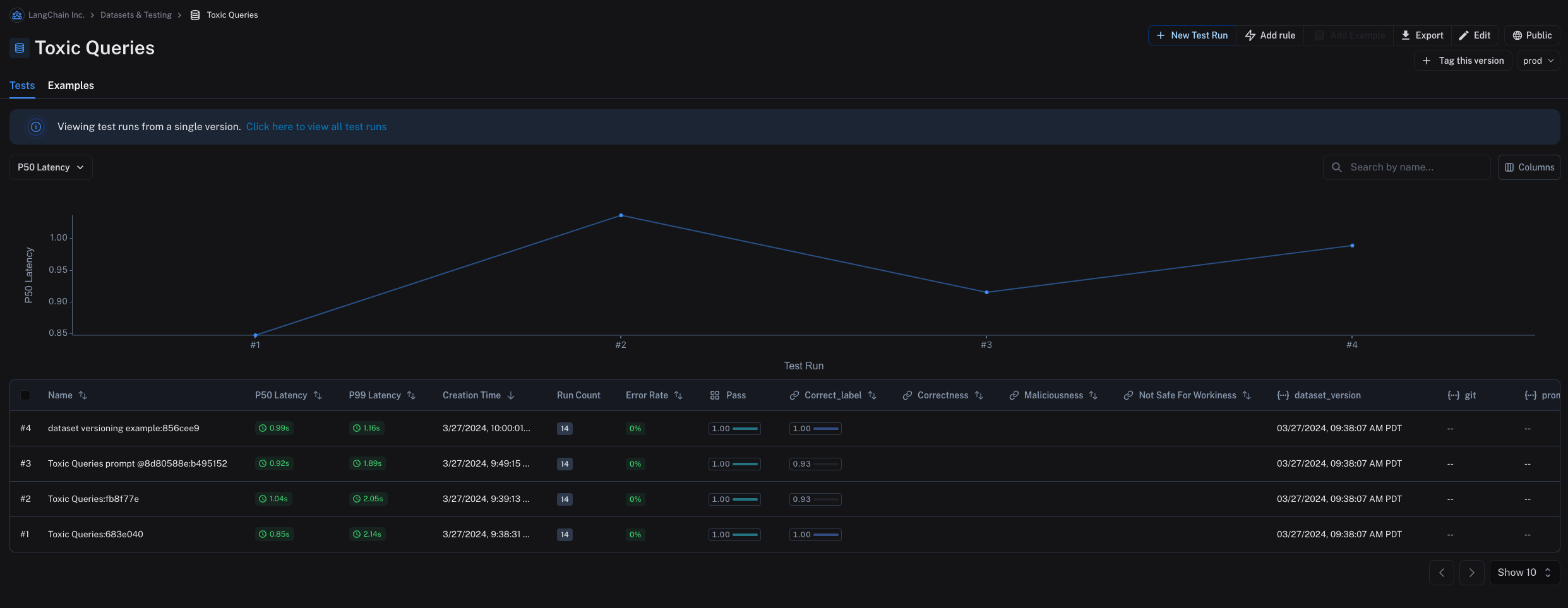
By default, the latest version of the dataset is shown in the Examples tab and experiments from all versions are shown in the Tests tab.
Tag a version
You can also tag versions of your dataset to give them a more human-readable name, which can be useful for marking important milestones in your dataset’s history. For example, you might tag a version of your dataset as “prod” and use it to run tests against your LLM pipeline. You can tag a version of your dataset in the UI by clicking on + Tag this version in the Examples tab.
Evaluate on a specific dataset version
You may find it helpful to refer to the following content before you read this section:
Use list_examples
You can use evaluate / aevaluate to pass in an iterable of examples to evaluate on a particular version of a dataset. Use list_examples / listExamples to fetch examples from a particular version tag using as_of / asOf and pass that into the data argument.
Evaluate on a split / filtered view of a dataset
You may find it helpful to refer to the following content before you read this section:
Evaluate on a filtered view of a dataset
You can use thelist_examples / listExamples method to fetch a subset of examples from a dataset to evaluate on.
One common workflow is to fetch examples that have a certain metadata key-value pair.
Evaluate on a dataset split
You can use thelist_examples / listExamples method to evaluate on one or multiple splits of your dataset. The splits parameter takes a list of the splits you would like to evaluate.
Share a dataset
Share a dataset publicly
From the Dataset & Experiments tab, select a dataset, click ⋮ (top right of the page), click Share Dataset. This will open a dialog where you can copy the link to the dataset.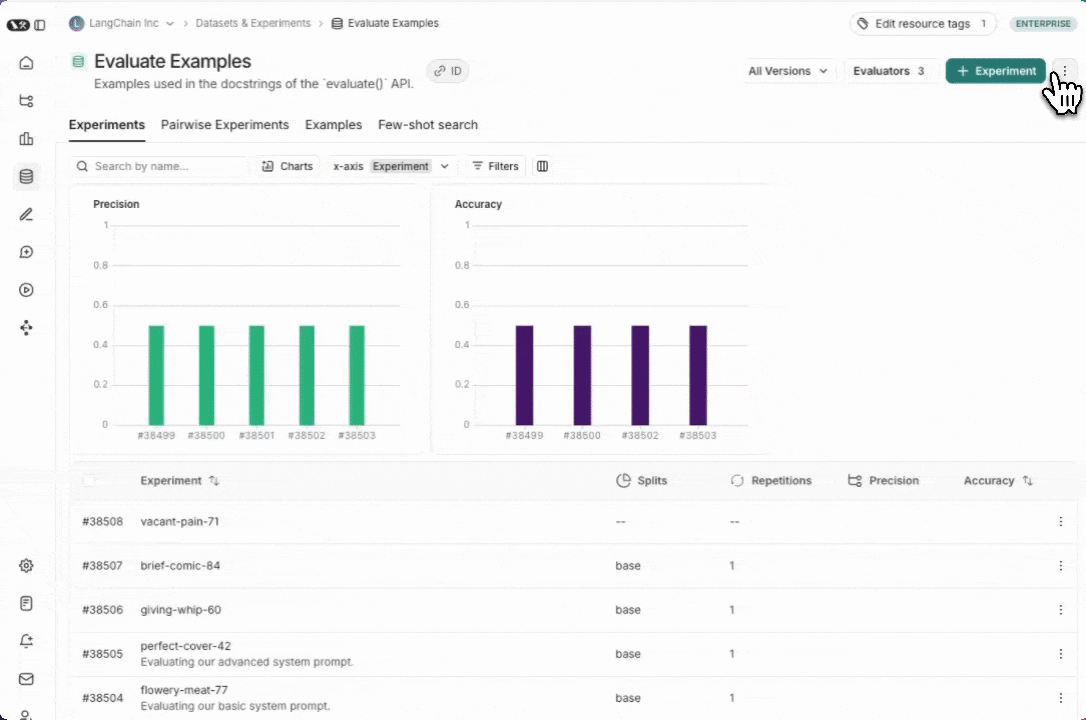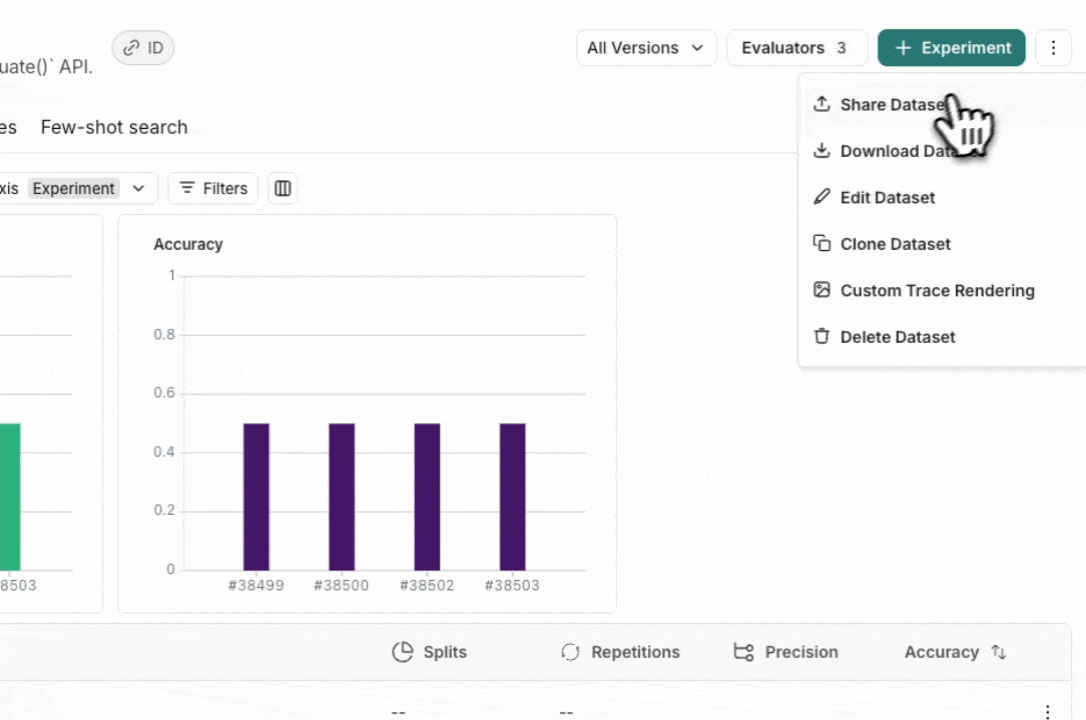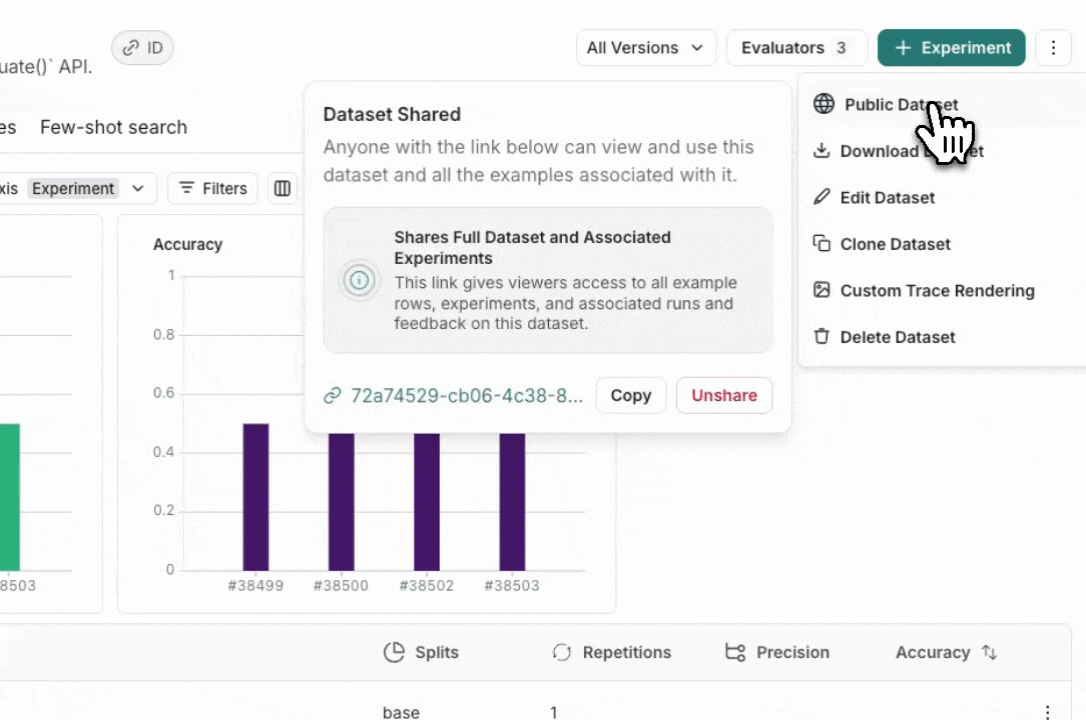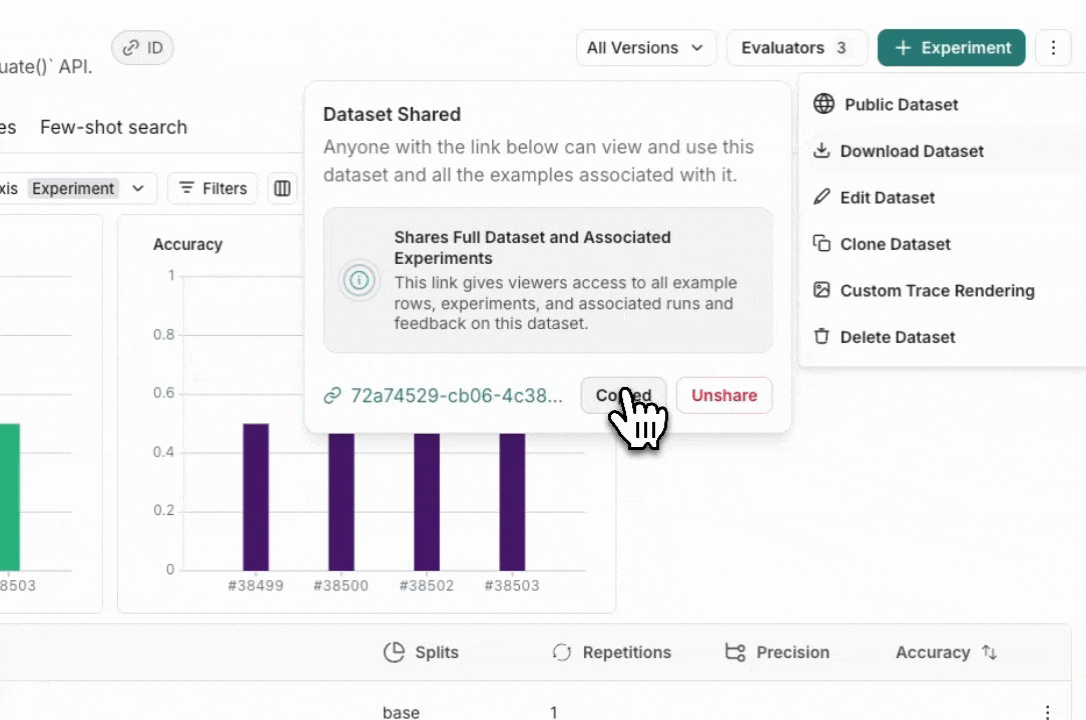
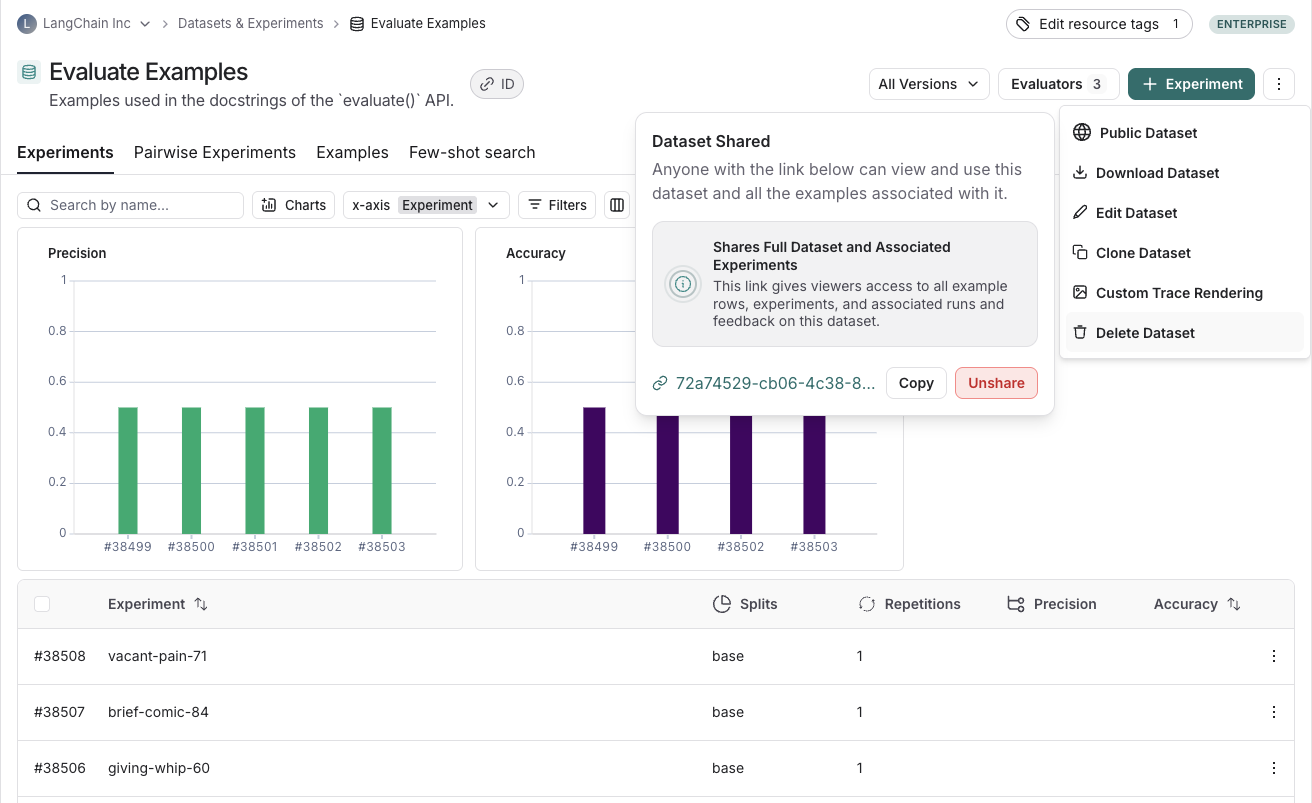
Unshare a dataset
-
Click on Unshare by clicking on Public in the upper right hand corner of any publicly shared dataset, then Unshare in the dialog.
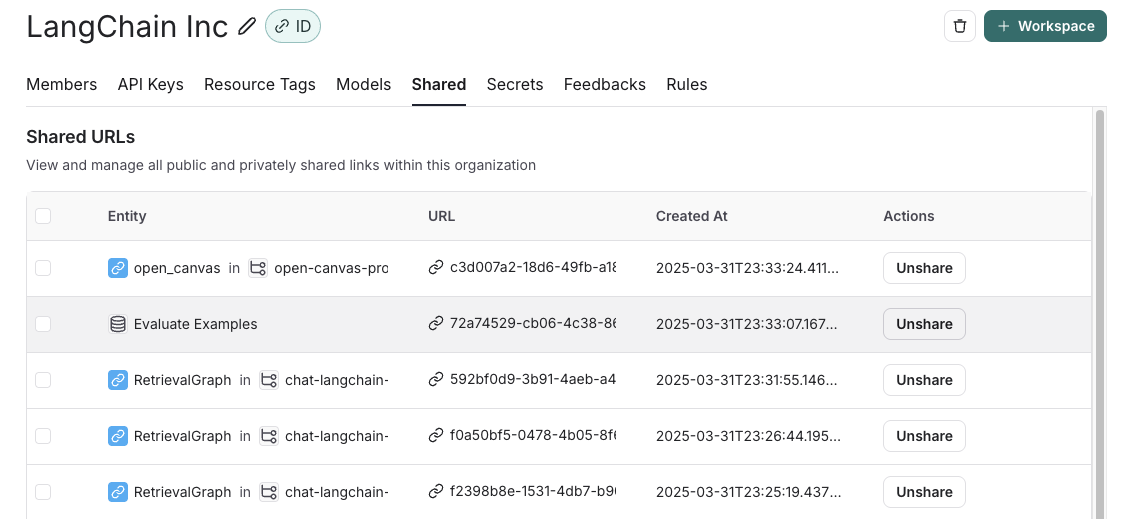
- Navigate to your organization’s list of publicly shared datasets, by clicking on Settings -> Shared URLs or this link, then click on Unshare next to the dataset you want to unshare.
Export a dataset
You can export your LangSmith dataset to a CSV, JSONL, or OpenAI’s fine tuning format from the LangSmith UI. From the Dataset & Experiments tab, select a dataset, click ⋮ (top right of the page), click Download Dataset.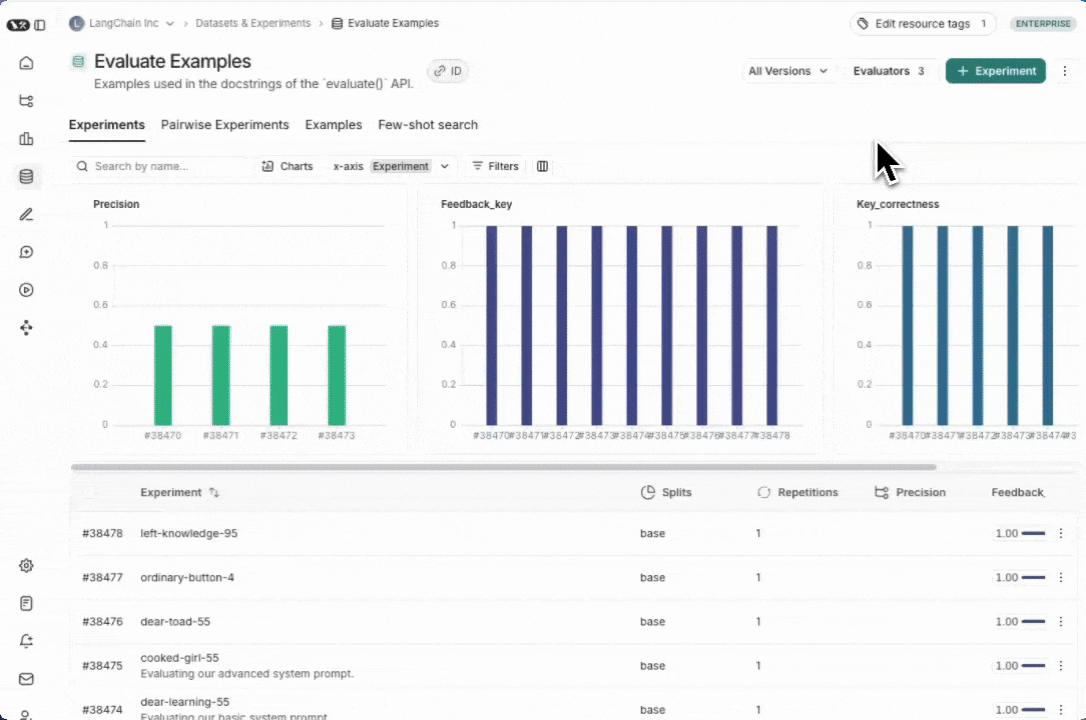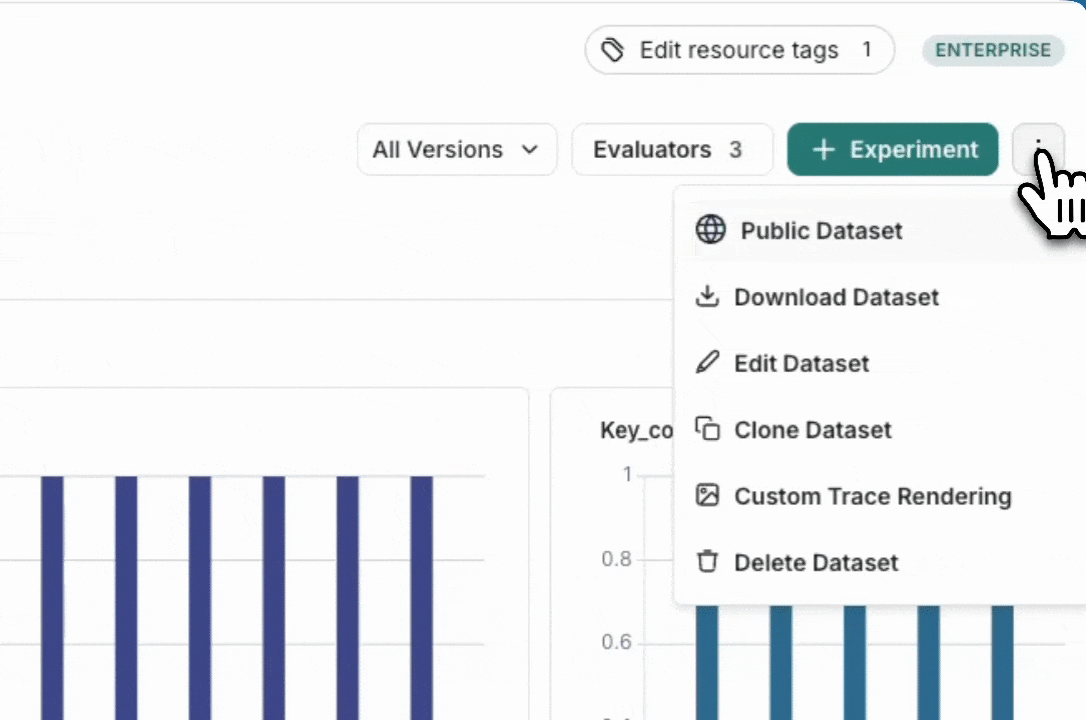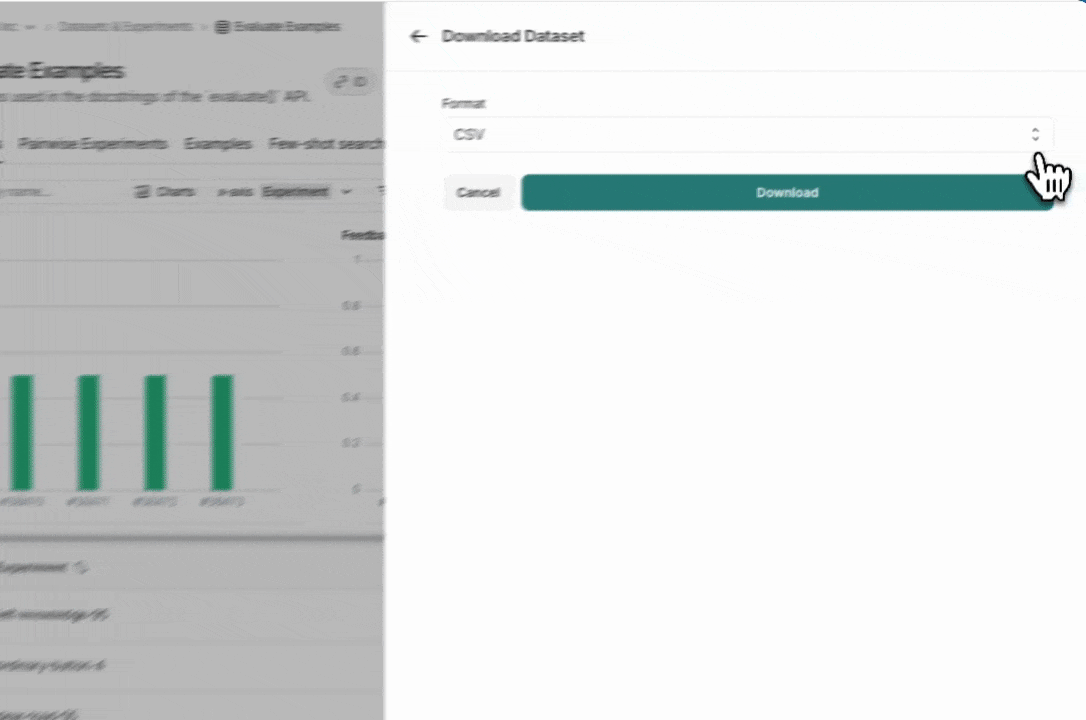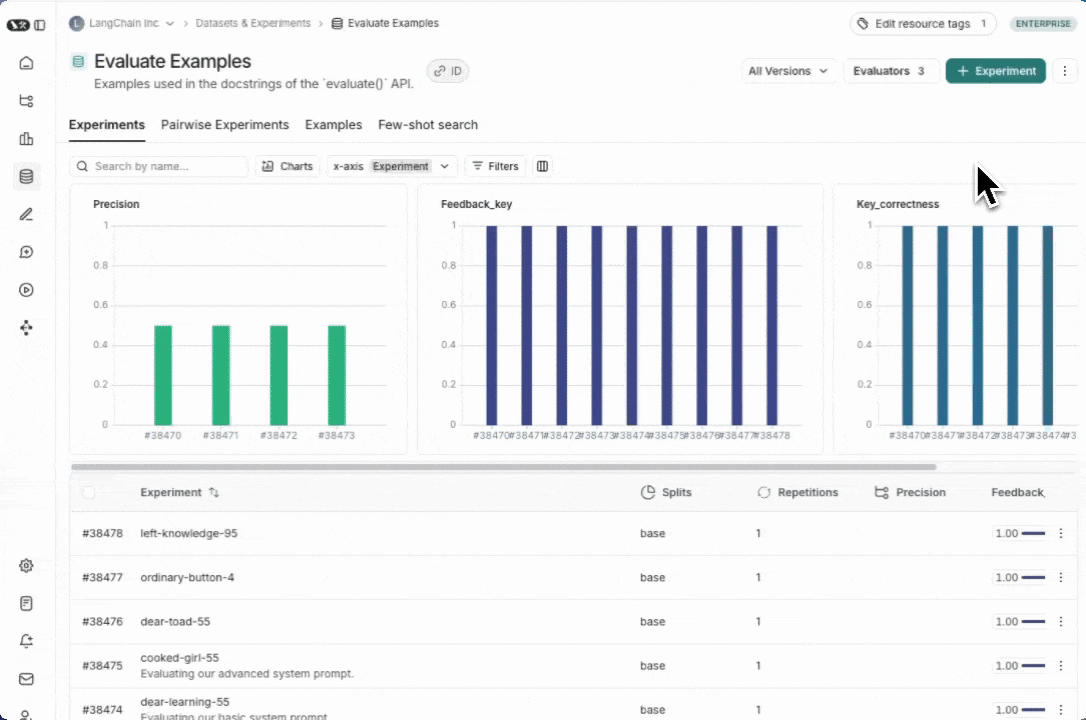
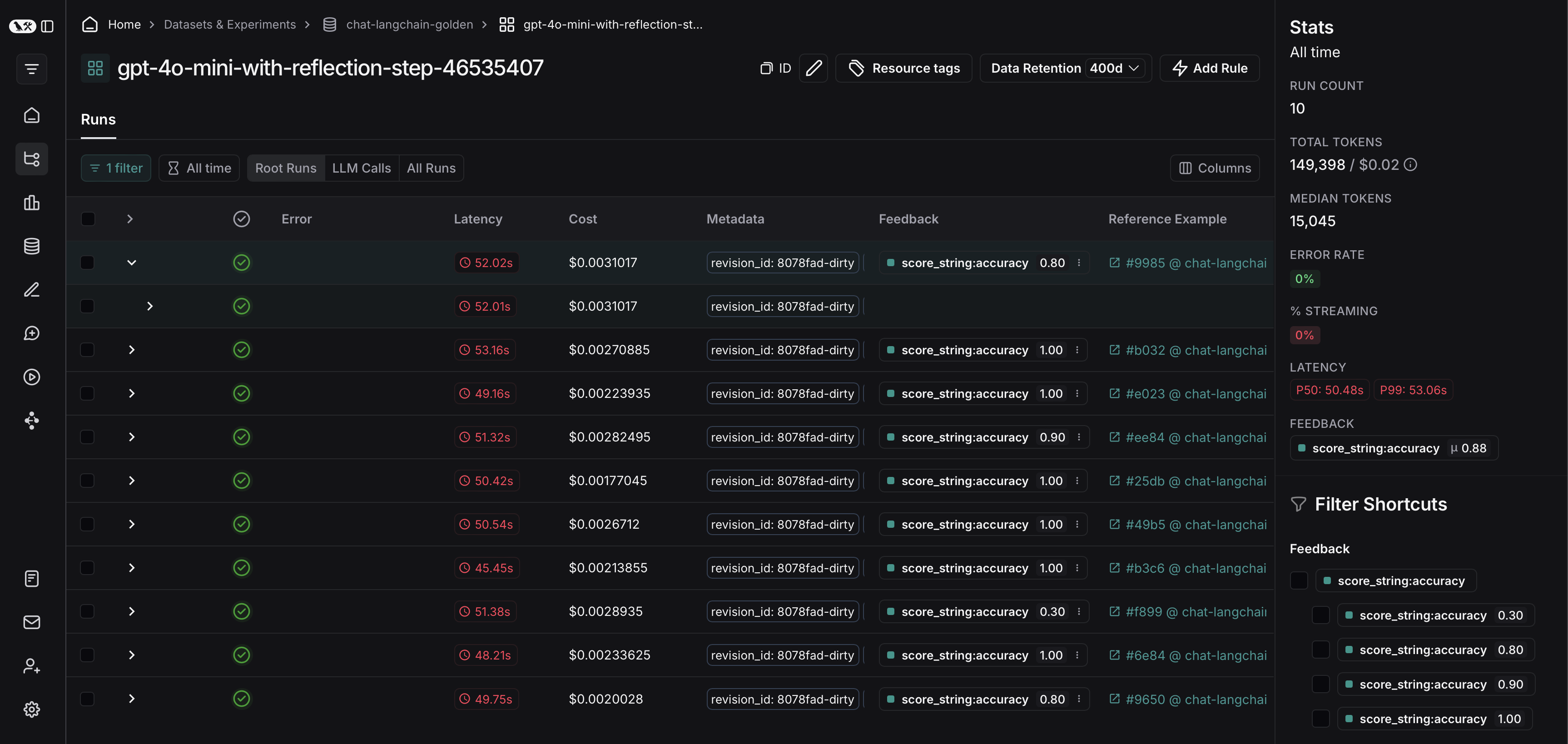
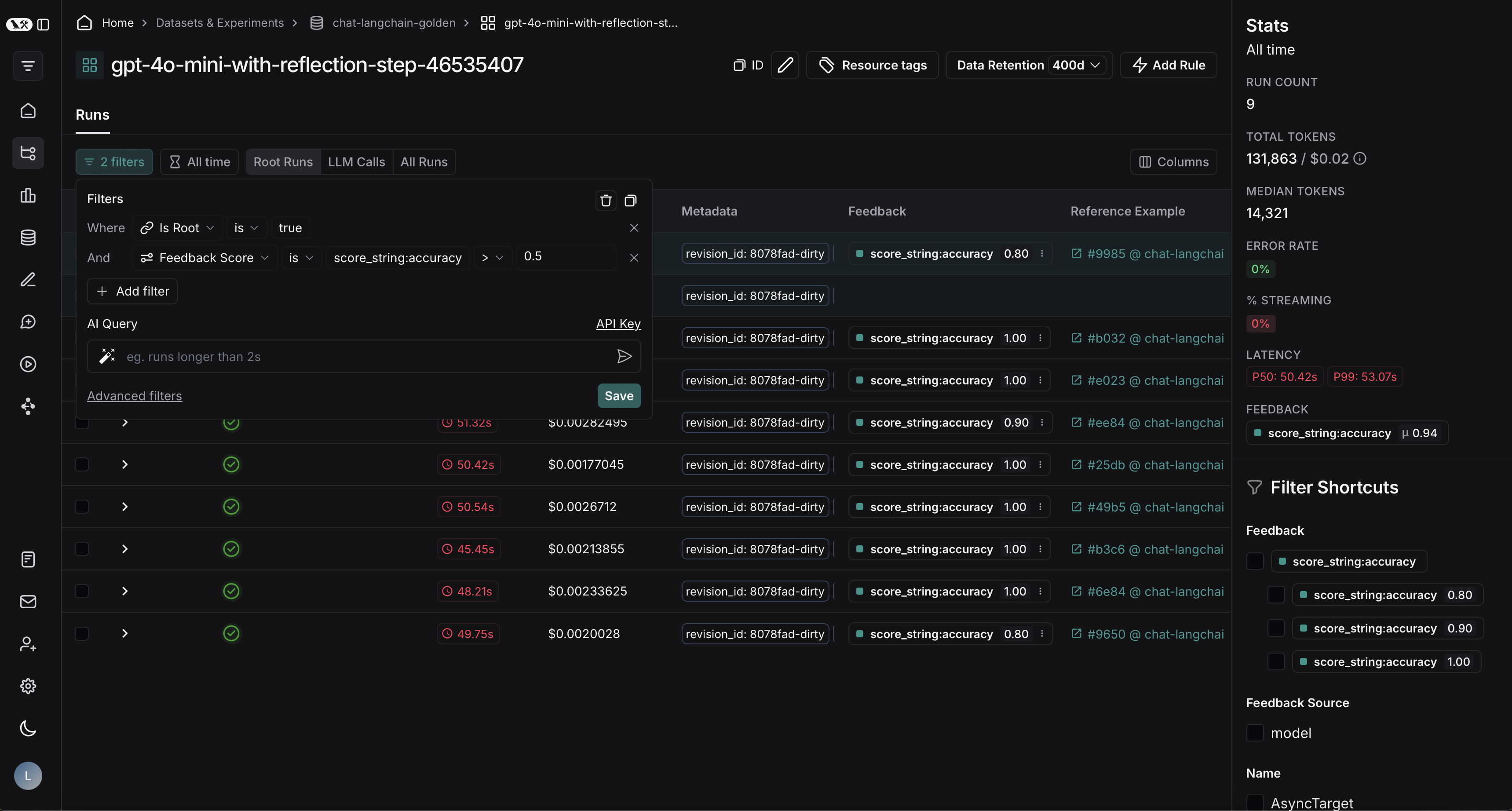
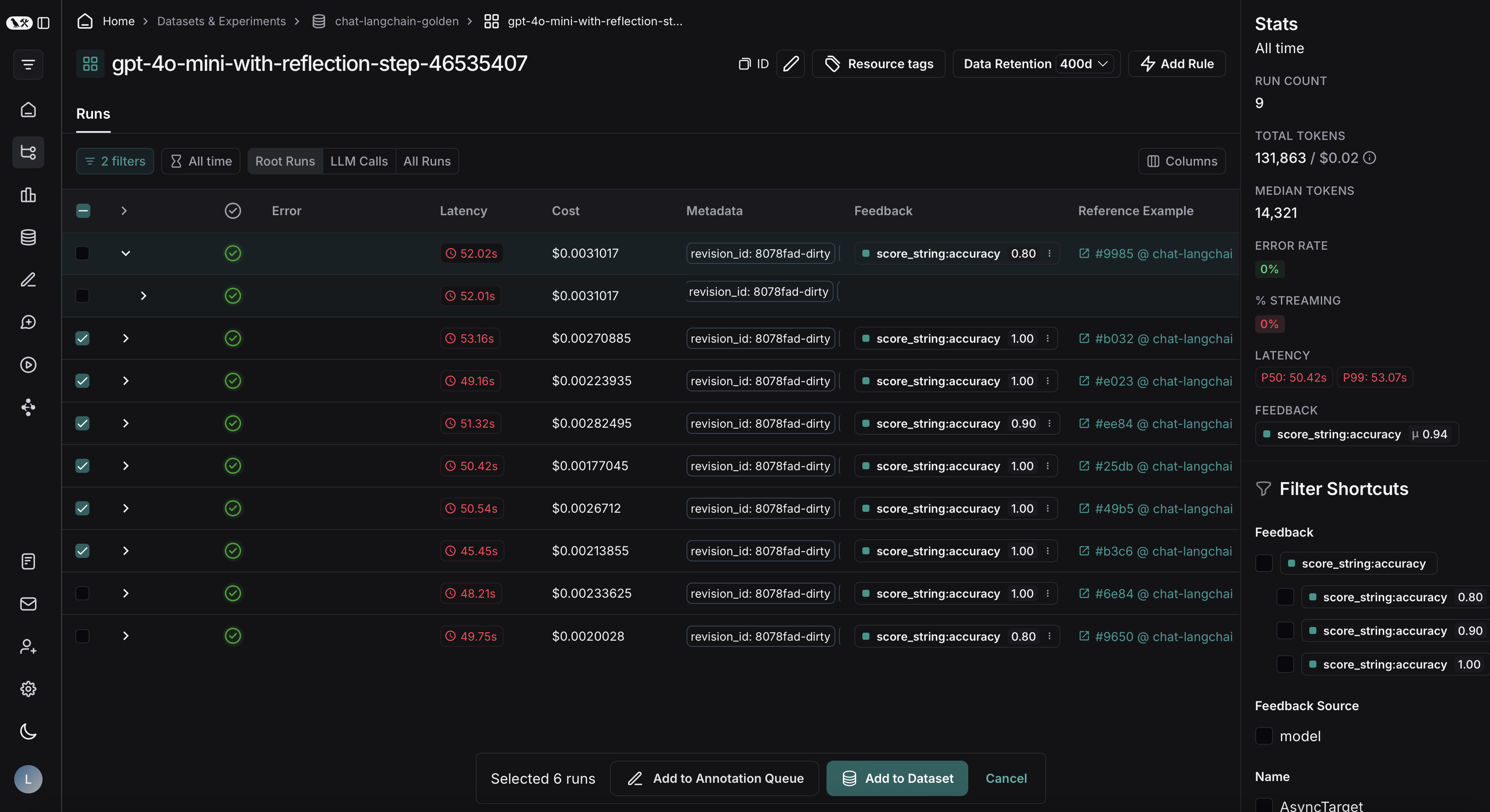
Export filtered traces from experiment to dataset
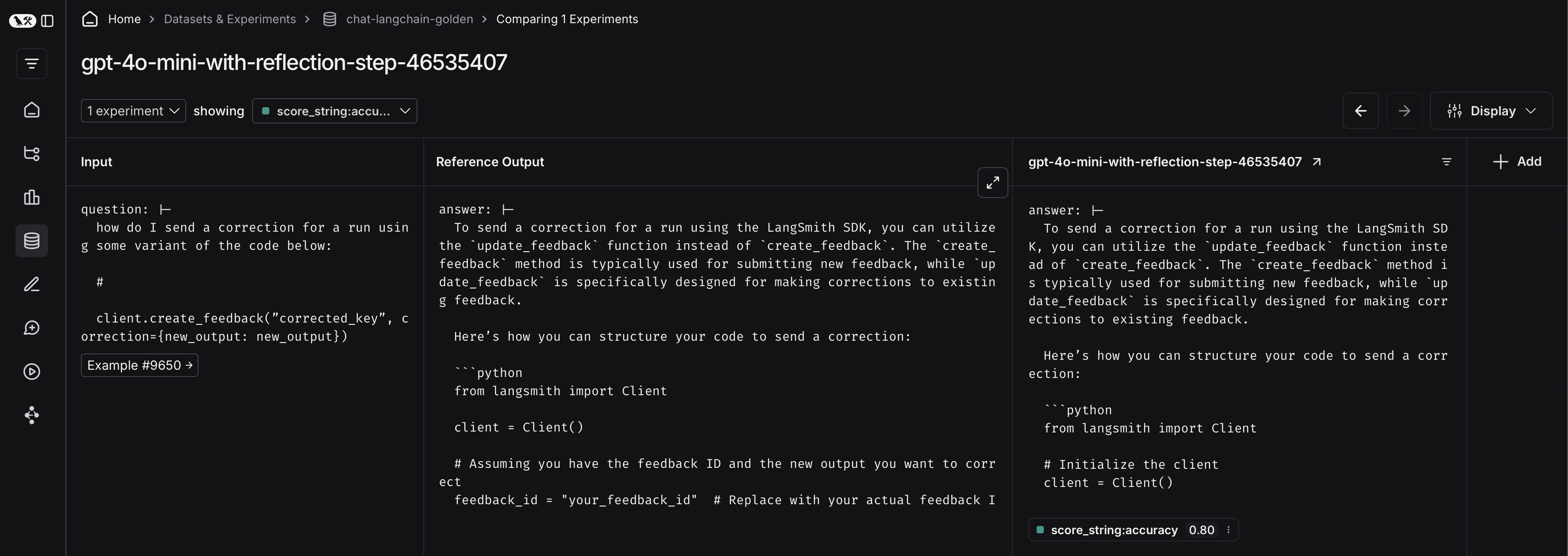
After running an offline evaluation in LangSmith, you may want to export traces that met some evaluation criteria to a dataset.View experiment traces
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.