

What to evaluate
Before building evaluations, identify what matters for your application. Break down your system into its critical components—LLM calls, retrieval steps, tool invocations, output formatting—and determine quality criteria for each. Start with manually curated examples. Create 5-10 examples of what “good” looks like for each critical component. These examples serve as your ground truth and inform which evaluation approaches to use. For instance:- RAG system: Examples of good retrievals (relevant documents) and good answers (accurate, complete).
- Agent: Examples of correct tool selection and proper argument formatting or trajectory that the agent took.
- Chatbot: Examples of helpful, on-brand responses that address user intent.
Offline and online evaluations
LangSmith supports two types of evaluations that serve different purposes in your development workflow:Offline evaluations
Use offline evaluations for pre-deployment testing:- Benchmarking: Compare multiple versions to find the best performer.
- Regression testing: Ensure new versions don’t degrade quality.
- Unit testing: Verify correctness of individual components.
- Backtesting: Test new versions against historical data.
Online evaluations
Use online evaluations for production monitoring:- Real-time monitoring: Track quality continuously on live traffic.
- Anomaly detection: Flag unusual patterns or edge cases.
- Production feedback: Identify issues to add to offline datasets.
Evaluation lifecycle
As you develop and deploy your application, your evaluation strategy evolves from pre-deployment testing to production monitoring. During development and testing, offline evaluations validate functionality against curated datasets. After deployment, online evaluations monitor production behavior on live traffic. As applications mature, both evaluation types work together in an iterative feedback loop to improve quality continuously.1. Development with offline evaluation
Before production deployment, use offline evaluations to validate functionality, benchmark different approaches, and build confidence. Follow the quickstart to run your first offline evaluation.2. Initial deployment with online evaluation
After deployment, use online evaluations to monitor production quality, detect unexpected issues, and collect real-world data. Learn how to configure online evaluations for production monitoring.3. Continuous improvement
Use both evaluation types together in an iterative feedback loop. Online evaluations surface issues that become offline test cases, offline evaluations validate fixes, and online evaluations confirm production improvements.Core evaluation targets
Evaluations run on different targets depending on whether they are offline or online.Targets for offline evaluation
Offline evaluations run on datasets and examples. The presence of reference outputs enables comparison between expected and actual results.Datasets
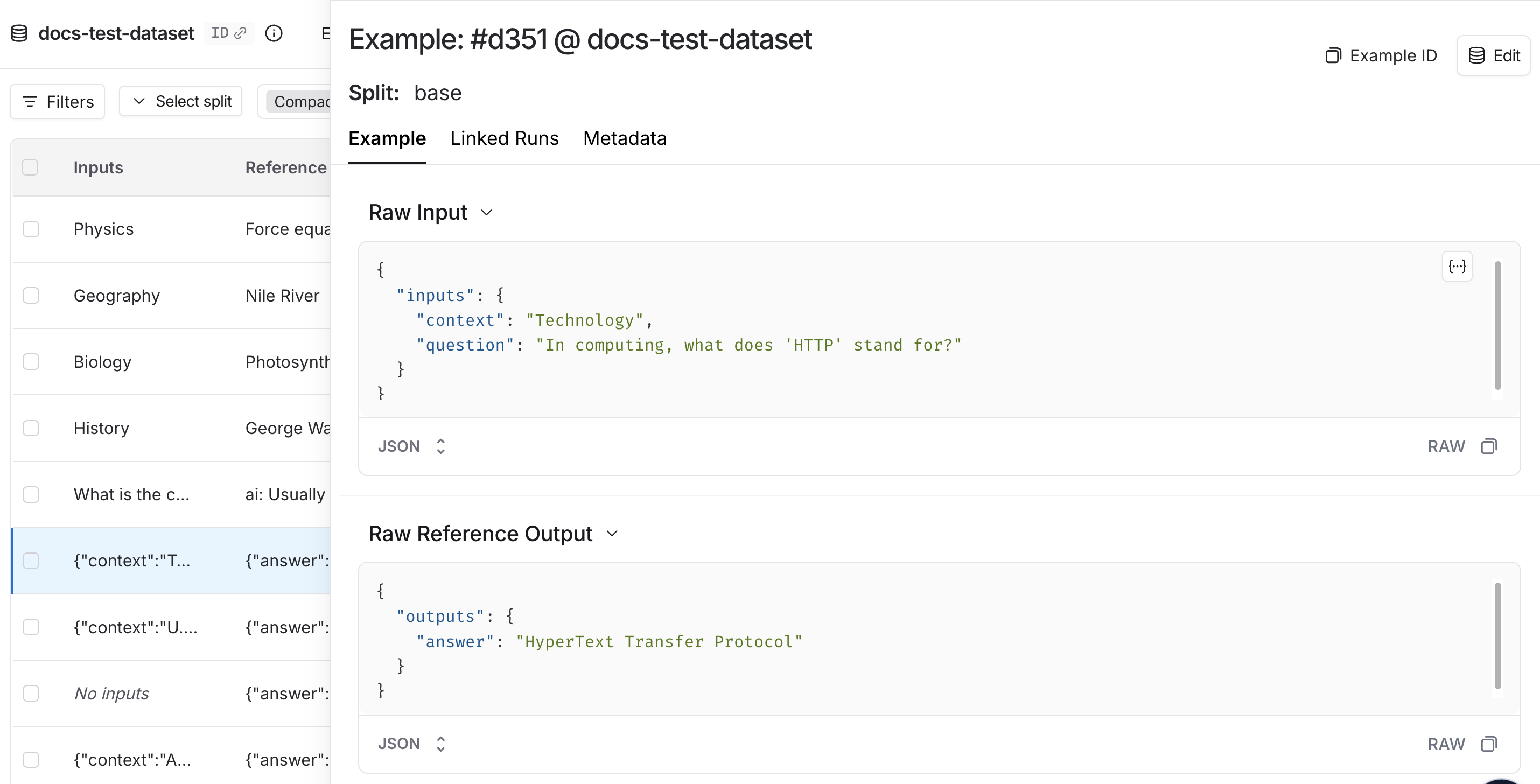
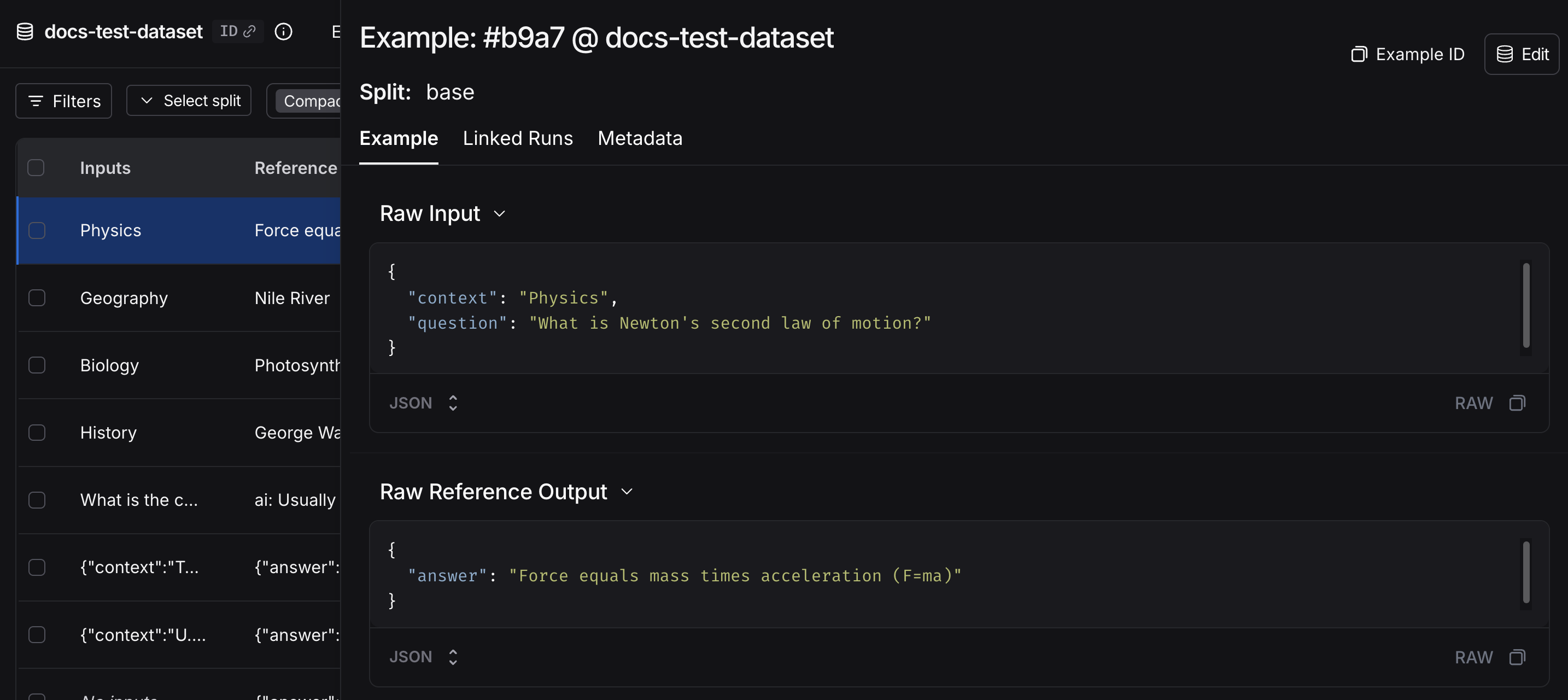
A dataset is a collection of examples used for evaluating an application. An example is a test input, reference output pair.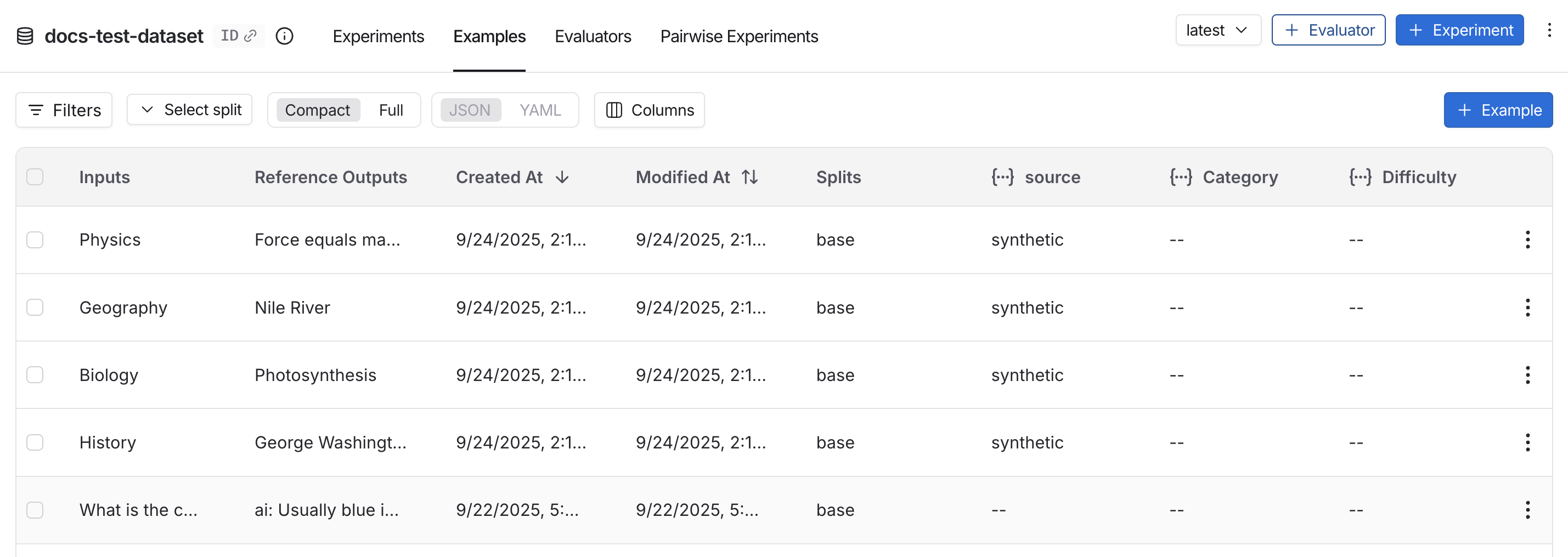
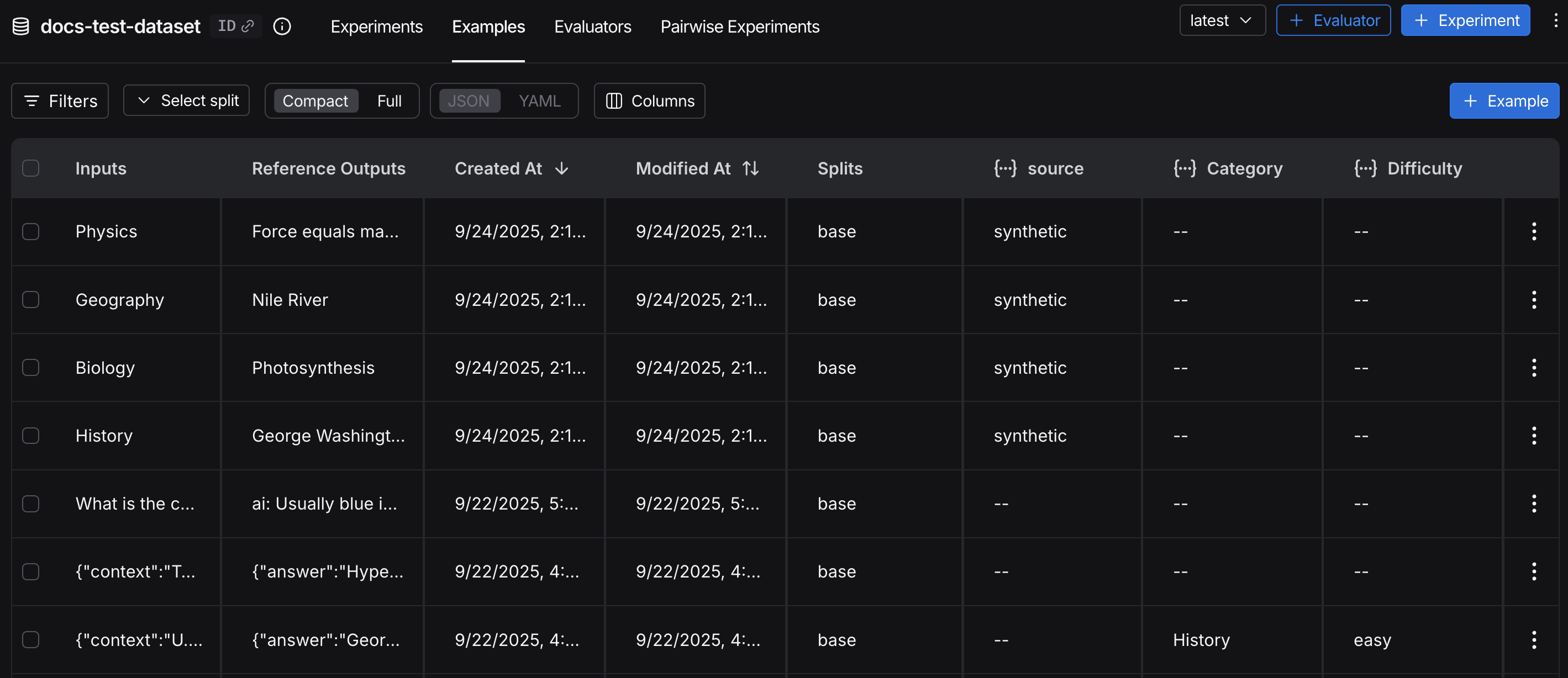
Examples
Each example consists of:- Inputs: a dictionary of input variables to pass to your application.
- Reference outputs (optional): a dictionary of reference outputs. These do not get passed to your application, they are only used in evaluators.
- Metadata (optional): a dictionary of additional information that can be used to create filtered views of a dataset.
Experiment
An experiment represents the results of evaluating a specific application version on a dataset. Each experiment captures outputs, evaluator scores, and execution traces for every example in the dataset.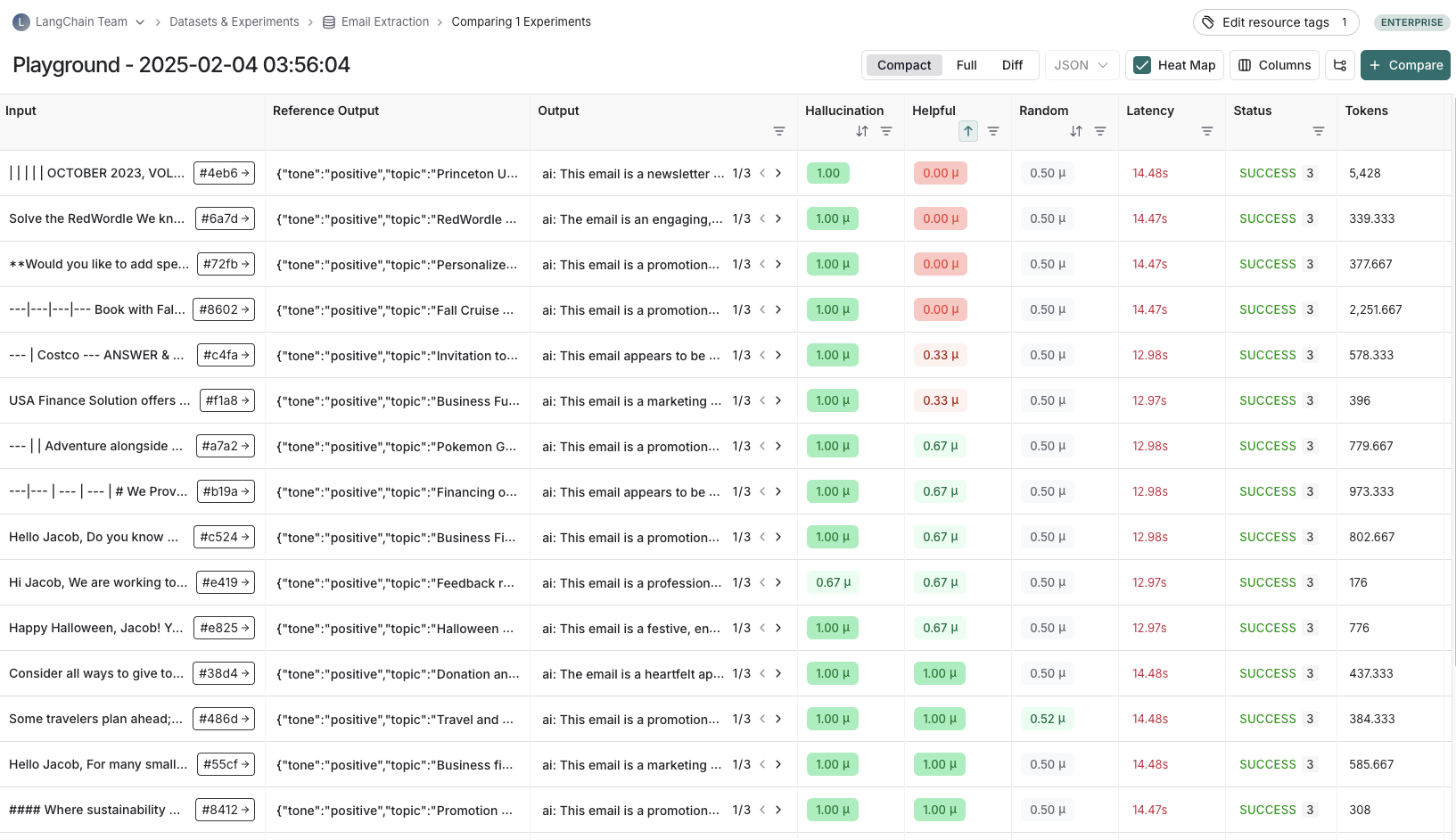
Targets for online evaluation
Online evaluations run on runs and threads from production traffic. Without reference outputs, evaluators focus on detecting issues, anomalies, and quality degradation in real-time.Runs
A run is a single execution trace from your deployed application. Each run contains:- Inputs: The actual user inputs your application received.
- Outputs: What your application actually returned.
- Intermediate steps: All the child runs (tool calls, LLM calls, and so on).
- Metadata: Tags, user feedback, latency metrics, etc.
Threads
Threads are collections of related runs representing multi-turn conversations. Online evaluators can run at the thread level to evaluate entire conversations rather than individual turns. This enables assessment of conversation-level properties like coherence across turns, topic maintenance, and user satisfaction throughout an interaction.Evaluators
Evaluators are workspace-level resources that score application performance. They provide the measurement layer for both offline and online evaluation, adapting their inputs based on what data is available. Because evaluators are scoped to the workspace, you can attach a single evaluator to multiple tracing projects and datasets without recreating it each time. Run evaluators using any of the following:- The Evaluators page, to attach them to tracing projects or datasets
- The Playground
- The LangSmith SDK (Python and TypeScript)
- Rules, to run them automatically on tracing projects or datasets
Attaching an evaluator to a tracing project or dataset
A single evaluator can be attached to many tracing projects and datasets. Configuration like sampling rate, filters, and spend limits is set per attached project or dataset, not per evaluator. View an evaluator’s attached projects and datasets under its Projects & Datasets tab.Evaluator inputs
Evaluator inputs differ based on evaluation type: Offline evaluators receive:- Example: The example from your dataset, containing inputs, reference outputs, and metadata.
- Run: The actual outputs and intermediate steps from running the application on the example inputs.
- Run: The production trace containing inputs, outputs, and intermediate steps (no reference outputs available).
Evaluator outputs
Evaluators return feedback, which is the scores from evaluation. Feedback is a dictionary or list of dictionaries. Each dictionary contains:key: The metric name.score|value: The metric value (scorefor numerical metrics,valuefor categorical metrics).comment(optional): Additional reasoning or explanation for the score.
Evaluation techniques
LangSmith supports several evaluation approaches:Human
Human evaluation involves manual review of application outputs and execution traces. This approach is often an effective starting point for evaluation. LangSmith provides tools to review application outputs and traces (all intermediate steps). Annotation queues Annotation queues streamline structured collection of human feedback on runs. They complement inline annotation by providing organized workflows with prescribed rubrics, team collaboration features, and progress tracking. LangSmith supports two queue types:- Single-run queues: Review one run at a time against custom rubric items. Useful for triaging issues or building datasets from production traces. Single-run queues also support assertions, free-form acceptance criteria that an offline evaluator can grade future runs against.
- Pairwise queues: Compare two runs side-by-side to judge which is better. Designed for fast A/B comparisons between experiments.
Code
Code evaluators are deterministic, rule-based functions. They work well for checks such as verifying the structure of a chatbot’s response is not empty, that generated code compiles, or that a classification matches exactly.LLM-as-judge
LLM-as-judge evaluators use LLMs to score application outputs. The grading rules and criteria are typically encoded in the LLM prompt. These evaluators can be:- Reference-free: Check if output contains offensive content or adheres to specific criteria.
- Reference-based: Compare output to a reference (e.g., check factual accuracy relative to the reference).
Pairwise
Pairwise evaluators compare outputs from two application versions using heuristics (e.g., which response is longer), LLMs (with pairwise prompts), or human reviewers. Pairwise evaluation works well when directly scoring an output is difficult but comparing two outputs is straightforward. For example, in summarization tasks, choosing the more informative of two summaries is often easier than assigning an absolute score to a single summary. Learn how run pairwise evaluations.Reference-free vs reference-based evaluators
Understanding whether an evaluator requires reference outputs is essential for determining when it can be used. Reference-free evaluators assess quality without comparing to expected outputs. These work for both offline and online evaluation:- Safety checks: Toxicity detection, PII detection, content policy violations
- Format validation: JSON structure, required fields, schema compliance
- Quality heuristics: Response length, latency, specific keywords
- Reference-free LLM-as-judge: Clarity, coherence, helpfulness, tone
- Correctness: Semantic similarity to reference answer
- Factual accuracy: Fact-checking against ground truth
- Exact match: Classification tasks with known labels
- Reference-based LLM-as-judge: Comparing output quality to a reference
Evaluation types
LangSmith supports various evaluation approaches for different stages of development and deployment. Understanding when to use each type helps build a comprehensive evaluation strategy. Offline and online evaluations serve different purposes:- Offline evaluation types test pre-deployment on curated datasets with reference outputs
- Online evaluation types monitor production behavior on live traffic without reference outputs
Best practices
Building datasets
There are various strategies for building datasets: Manually curated examples This is the recommended starting point. Create 10–20 high-quality examples covering common scenarios and edge cases. These examples define what “good” looks like for your application. Historical traces Once in production, convert real traces into examples. For high-traffic applications:- User feedback: Add runs that received negative feedback to test against.
- Heuristics: Identify interesting runs (e.g., long latency, errors).
- LLM feedback: Use LLMs to detect noteworthy conversations.
Dataset organization
Splits Splits are named subsets of a dataset used to segment examples into separate groups. Common patterns include:- ML-style splits: divide examples into training, validation, and test sets to avoid overfitting, where a model performs well on training data but poorly on unseen data.
- Category-based splits: evaluate different input types separately when a dataset spans multiple task categories.
- Staged rollout: keep exploratory examples isolated until you’re ready to include them in the main evaluation set.
Human feedback collection
Human feedback often provides the most valuable assessment, particularly for subjective quality dimensions. Annotation queues Annotation queues enable structured collection of human feedback. Flag specific runs for review, collect annotations in a streamlined interface, and transfer annotated runs to datasets for future evaluations. Annotation queues complement inline annotation by offering additional capabilities: grouping runs, specifying criteria, and configuring reviewer permissions.Evaluations vs testing
Testing and evaluation are similar but distinct concepts. Evaluation measures performance according to metrics. Metrics can be fuzzy or subjective, and prove more useful in relative terms. They typically compare systems against each other. Testing asserts correctness. A system can only be deployed if it passes all tests. Evaluation metrics can be converted into tests. For example, regression tests can assert that new versions must outperform baseline versions on relevant metrics. Run tests and evaluations together for efficiency when systems are expensive to run. Evaluations can be written using standard testing tools like pytest or Vitest/Jest.Quick reference: Offline vs online evaluation
The following table summarizes the key differences between offline and online evaluations:Connect these docs to Claude, VSCode, and more via MCP for real-time answers.