

Setup
Installlanggraph:
Define and update state
Here we show how to define and update state in LangGraph. We will demonstrate:- How to use state to define a graph’s schema
- How to use reducers to control how state updates are processed.
Define state
State in LangGraph can be aTypedDict, Pydantic model, or dataclass. Below we will use TypedDict. See Use Pydantic models for graph state for detail on using Pydantic.
By default, graphs will have the same input and output schema, and the state determines that schema. See Define input and output schemas for how to define distinct input and output schemas.
Let’s consider a simple example using messages. This represents a versatile formulation of state for many LLM applications. See our concepts page for more detail.
Update state
Let’s build an example graph with a single node. Our node is just a Python function that reads our graph’s state and makes updates to it. The first argument to this function will always be the state:StateGraph to define a graph that operates on this state. We then use add_node populate our graph.
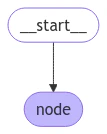
- We kicked off invocation by updating a single key of the state.
- We receive the entire state in the invocation result.
Process state updates with reducers
Each key in the state can have its own independent reducer function, which controls how updates from nodes are applied. If no reducer function is explicitly specified then it is assumed that all updates to the key should override it. ForTypedDict state schemas, we can define reducers by annotating the corresponding field of the state with a reducer function.
In the earlier example, our node updated the "messages" key in the state by appending a message to it. Below, we add a reducer to this key, such that updates are automatically appended:
MessagesState
In practice, there are additional considerations for updating lists of messages:- We may wish to update an existing message in the state.
- We may want to accept short-hands for message formats, such as OpenAI format.
add_messages that handles these considerations:
MessagesState for convenience, so that we can have:
Bypass reducers with Overwrite
In some cases, you may want to bypass a reducer and directly overwrite a state value. LangGraph provides the Overwrite type for this purpose. When a node returns a value wrapped with Overwrite, the reducer is bypassed and the channel is set directly to that value.
This is useful when you want to reset or replace accumulated state rather than merge it with existing values.
"__overwrite__":
Define input and output schemas
By default,StateGraph operates with a single schema, and all nodes are expected to communicate using that schema. However, it’s also possible to define distinct input and output schemas for a graph.
When distinct schemas are specified, an internal schema will still be used for communication between nodes. The input schema ensures that the provided input matches the expected structure, while the output schema filters the internal data to return only the relevant information according to the defined output schema.
Below, we’ll see how to define distinct input and output schema.
Pass private state between nodes
In some cases, you may want nodes to exchange information that is crucial for intermediate logic but doesn’t need to be part of the main schema of the graph. This private data is not relevant to the overall input/output of the graph and should only be shared between certain nodes. Below, we’ll create an example sequential graph consisting of three nodes (node_1, node_2 and node_3), where private data is passed between the first two steps (node_1 and node_2), while the third step (node_3) only has access to the public overall state.Use pydantic models for graph state
A StateGraph accepts astate_schema argument on initialization that specifies the “shape” of the state that the nodes in the graph can access and update.
In our examples, we typically use a python-native TypedDict or dataclass for state_schema, but state_schema can be any type.
Here, we’ll see how a Pydantic BaseModel can be used for state_schema to add run-time validation on inputs.
Known Limitations
- Currently, the output of the graph will NOT be an instance of a pydantic model.
- Run-time validation only occurs on inputs to the first node in the graph, not on subsequent nodes or outputs.
- The validation error trace from pydantic does not show which node the error arises in.
- Pydantic’s recursive validation can be slow. For performance-sensitive applications, you may want to consider using a
dataclassinstead.
Serialization Behavior
Serialization Behavior
When using Pydantic models as state schemas, it’s important to understand how serialization works, especially when:
- Passing Pydantic objects as inputs
- Receiving outputs from the graph
- Working with nested Pydantic models
Runtime Type Coercion
Runtime Type Coercion
Pydantic performs runtime type coercion for certain data types. This can be helpful but also lead to unexpected behavior if you’re not aware of it.
Working with Message Models
Working with Message Models
When working with LangChain message types in your state schema, there are important considerations for serialization. You should use
AnyMessage (rather than BaseMessage) for proper serialization/deserialization when using message objects over the wire.Add runtime configuration
Sometimes you want to be able to configure your graph when calling it. For example, you might want to be able to specify what LLM or system prompt to use at runtime, without polluting the graph state with these parameters. To add runtime configuration:- Specify a schema for your configuration
- Add the configuration to the function signature for nodes or conditional edges
- Pass the configuration into the graph.
Extended example: specifying LLM at runtime
Extended example: specifying LLM at runtime
Below we demonstrate a practical example in which we configure what LLM to use at runtime. We will use both OpenAI and Anthropic models.
Extended example: specifying model and system message at runtime
Extended example: specifying model and system message at runtime
Below we demonstrate a practical example in which we configure two parameters: the LLM and system message to use at runtime.
Add retry policies
There are many use cases where you may wish for your node to have a custom retry policy, for example if you are calling an API, querying a database, or calling an LLM, etc. LangGraph lets you add retry policies to nodes. To configure a retry policy, pass theretry_policy parameter to the add_node. The retry_policy parameter takes in a RetryPolicy named tuple object. Below we instantiate a RetryPolicy object with the default parameters and associate it with a node:
retry_on parameter uses the default_retry_on function, which retries on any exception except for the following:
ValueErrorTypeErrorArithmeticErrorImportErrorLookupErrorNameErrorSyntaxErrorRuntimeErrorReferenceErrorStopIterationStopAsyncIterationOSError
requests and httpx it only retries on 5xx status codes.
Extended example: customizing retry policies
Extended example: customizing retry policies
Consider an example in which we are reading from a SQL database. Below we pass two different retry policies to nodes:
Set node timeouts
Use thetimeout parameter with add_node to limit how long a single async node invocation can run. Provide the timeout in seconds or as a datetime.timedelta.
timeout on a sync node, LangGraph raises an error when the graph is compiled because sync Python execution cannot be safely canceled in-process.
When a node exceeds its timeout, LangGraph raises NodeTimeoutError, which subclasses Python’s built-in TimeoutError. If the node has a retry_policy that retries TimeoutError or NodeTimeoutError, the timed-out attempt is retried. The timeout applies to each attempt independently, so the timer resets for every retry.
Timed-out attempts do not commit their buffered writes. This prevents state updates or child-task scheduling from leaking out after the timeout boundary.
Configure node timeouts
Thetimeout= parameter on add_node caps how long a single async node attempt may run. Pass a number (seconds), a timedelta, or a TimeoutPolicy for finer control over run and idle timeouts. When the limit is exceeded, LangGraph raises NodeTimeoutError and lets the retry policy decide whether to retry.
Per-node timeouts require
langgraph>=1.2.runtime.heartbeat().
Handle node errors
Theerror_handler= parameter on add_node registers a function that runs after a node fails and all retries are exhausted. The handler receives the current state and a typed NodeError with failure context, and can route to a recovery branch via Command:
Node-level error handlers require
langgraph>=1.2.Command routing.
Access execution info inside a node
You can access execution identity and retry information viaruntime.execution_info. This surfaces thread, run, and checkpoint identifiers as well as retry state, without needing to read from config directly.
Access thread and run IDs
Useexecution_info to access the thread ID, run ID, and other identity fields inside a node:
Adjust behavior based on retry state
When a node has a retry policy, useexecution_info to inspect the current attempt number and switch to a fallback after the first attempt fails:
execution_info is available on the Runtime object even without a retry policy — node_attempt defaults to 1 and node_first_attempt_time is set to the time the node starts executing.
Access server info inside a node
When your graph runs on LangGraph Server, you can access server-specific metadata viaruntime.server_info. This surfaces the assistant ID, graph ID, and authenticated user without needing to read from config metadata or configurable keys directly.
server_info is None when the graph is not running on LangGraph Server (e.g., during local development or testing).
Requires
deepagents>=0.5.0 (or langgraph>=1.1.5) for runtime.execution_info and runtime.server_info.Access drain state inside a node
When a graceful shutdown has been requested,runtime.drain_requested is True. Read this inside a node to skip expensive work before the next superstep boundary:
Requires
langgraph>=1.2. See Graceful shutdown for the full RunControl API.Add node caching
Node caching is useful in cases where you want to avoid repeating operations, like when doing something expensive (either in terms of time or cost). LangGraph lets you add individualized caching policies to nodes in a graph. To configure a cache policy, pass thecache_policy parameter to the add_node function. In the following example, a CachePolicy object is instantiated with a time to live of 120 seconds and the default key_func generator. Then it is associated with a node:
cache argument when compiling the graph. The example below uses InMemoryCache to set up a graph with in-memory cache, but SqliteCache is also available.
Create a sequence of steps
Prerequisites
This guide assumes familiarity with the above section on state.
- How to build a sequential graph
- Built-in short-hand for constructing similar graphs.
add_node and add_edge methods of our graph:
.add_sequence:
Why split application steps into a sequence with LangGraph?
Why split application steps into a sequence with LangGraph?
LangGraph makes it easy to add an underlying persistence layer to your application.
This allows state to be checkpointed in between the execution of nodes, so your LangGraph nodes govern:Our nodes are just Python functions that read our graph’s state and make updates to it. The first argument to this function will always be the state:Finally, we define the graph. We use StateGraph to define a graph that operates on this state.We will then use Note that:LangGraph provides built-in utilities for visualizing your graph. Let’s inspect our sequence. See Visualize your graph for detail on visualization.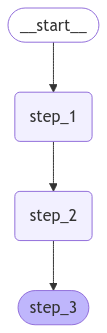
- How state updates are checkpointed
- How interruptions are resumed in human-in-the-loop workflows
- How we can “rewind” and branch-off executions using LangGraph’s time travel features
- Populate a value in a key of the state
- Update the same value
- Populate a different value
Note that when issuing updates to the state, each node can just specify the value of the key it wishes to update.By default, this will overwrite the value of the corresponding key. You can also use reducers to control how updates are processed—for example, you can append successive updates to a key instead. See Process state updates with reducers for more detail.
add_node and add_edge to populate our graph and define its control flow.add_edgetakes the names of nodes, which for functions defaults tonode.__name__.- We must specify the entry point of the graph. For this we add an edge with the START node.
- The graph halts when there are no more nodes to execute.
- We kicked off invocation by providing a value for a single state key. We must always provide a value for at least one key.
- The value we passed in was overwritten by the first node.
- The second node updated the value.
- The third node populated a different value.
Create branches
Parallel execution of nodes is essential to speed up overall graph operation. LangGraph offers native support for parallel execution of nodes, which can significantly enhance the performance of graph-based workflows. This parallelization is achieved through fan-out and fan-in mechanisms, utilizing both standard edges and conditional_edges. Below are some examples showing how to add create branching dataflows that work for you.Run graph nodes in parallel
In this example, we fan out fromNode A to B and C and then fan in to D. With our state, we specify the reducer add operation. This will combine or accumulate values for the specific key in the State, rather than simply overwriting the existing value. For lists, this means concatenating the new list with the existing list. See the above section on state reducers for more detail on updating state with reducers.
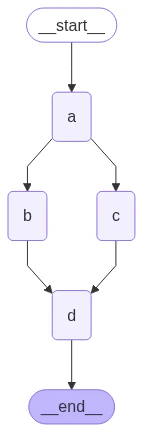
In the above example, nodes
"b" and "c" are executed concurrently in the same superstep. Because they are in the same step, node "d" executes after both "b" and "c" are finished.Importantly, updates from a parallel superstep may not be ordered consistently. If you need a consistent, predetermined ordering of updates from a parallel superstep, you should write the outputs to a separate field in the state together with a value with which to order them.Exception handling?
Exception handling?
LangGraph executes nodes within supersteps, meaning that while parallel branches are executed in parallel, the entire superstep is transactional. If any of these branches raises an exception, none of the updates are applied to the state (the entire superstep errors).Importantly, when using a checkpointer, results from successful nodes within a superstep are saved, and don’t repeat when resumed.If you have error-prone (perhaps want to handle flakey API calls), LangGraph provides two ways to address this:
- You can write regular python code within your node to catch and handle exceptions.
- You can set a retry_policy to direct the graph to retry nodes that raise certain types of exceptions. Only failing branches are retried, so you needn’t worry about performing redundant work.
Defer node execution
Deferring node execution is useful when you want to delay the execution of a node until all other pending tasks are completed. This is particularly relevant when branches have different lengths, which is common in workflows like map-reduce flows. The above example showed how to fan-out and fan-in when each path was only one step. But what if one branch had more than one step? Let’s add a node"b_2" in the "b" branch:
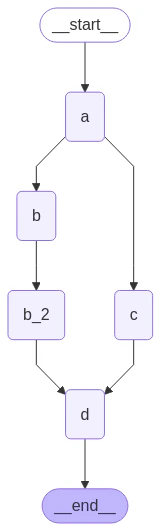
"b" and "c" are executed concurrently in the same superstep. We set defer=True on node d so it will not execute until all pending tasks are finished. In this case, this means that "d" waits to execute until the entire "b" branch is finished.
Conditional branching
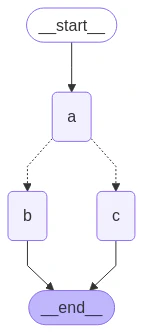
If your fan-out should vary at runtime based on the state, you can useadd_conditional_edges to select one or more paths using the graph state. See example below, where node a generates a state update that determines the following node.
Map-Reduce and the send API
LangGraph supports map-reduce and other advanced branching patterns using the Send API. Here is an example of how to use it: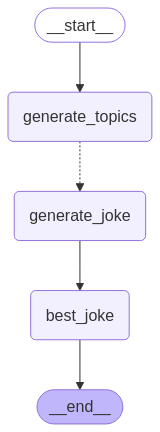
Create and control loops
When creating a graph with a loop, we require a mechanism for terminating execution. This is most commonly done by adding a conditional edge that routes to the END node once we reach some termination condition. You can also set the graph recursion limit when invoking or streaming the graph. The recursion limit sets the number of super-steps that the graph is allowed to execute before it raises an error. Read more about the recursion limit concept. Let’s consider a simple graph with a loop to better understand how these mechanisms work. When creating a loop, you can include a conditional edge that specifies a termination condition:"recursion_limit" in the config. This will raise a GraphRecursionError, which you can catch and handle:
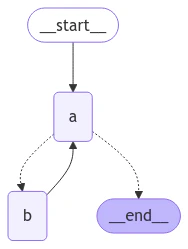
"a" is a tool-calling model, and node "b" represents the tools.
In our route conditional edge, we specify that we should end after the "aggregate" list in the state passes a threshold length.
Invoking the graph, we see that we alternate between nodes "a" and "b" before terminating once we reach the termination condition.
Impose a recursion limit
In some applications, we may not have a guarantee that we will reach a given termination condition. In these cases, we can set the graph’s recursion limit. This will raise aGraphRecursionError after a given number of supersteps. We can then catch and handle this exception:
Extended example: return state on hitting recursion limit
Extended example: return state on hitting recursion limit
Instead of raising
GraphRecursionError, we can introduce a new key to the state that keeps track of the number of steps remaining until reaching the recursion limit. We can then use this key to determine if we should end the run.LangGraph implements a special RemainingSteps annotation. Under the hood, it creates a ManagedValue channel — a state channel that will exist for the duration of our graph run and no longer.Extended example: loops with branches
Extended example: loops with branches
To better understand how the recursion limit works, let’s consider a more complex example. Below we implement a loop, but one step fans out into two nodes: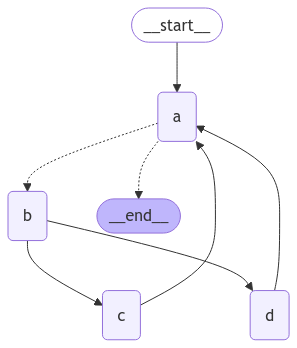
- Node A
- Node B
- Nodes C and D
- Node A
- …
Async
Using the async programming paradigm can produce significant performance improvements when running IO-bound code concurrently (e.g., making concurrent API requests to a chat model provider). To convert async implementation of the graph to an async implementation, you will need to:
- Update
nodesuseasync definstead ofdef. - Update the code inside to use
awaitappropriately. - Invoke the graph with
.ainvokeor.astreamas desired.
async variants of all the sync methods it’s typically fairly quick to upgrade a sync graph to an async graph.
See example below. To demonstrate async invocations of underlying LLMs, we will include a chat model:
- OpenAI
- Anthropic
- Azure
- Google Gemini
- AWS Bedrock
- HuggingFace
- OpenRouter
Combine control flow and state updates with Command
It can be useful to combine control flow (edges) and state updates (nodes). For example, you might want to BOTH perform state updates AND decide which node to go to next in the SAME node. LangGraph provides a way to do so by returning a Command object from node functions:
StateGraph with the above nodes. Notice that the graph doesn’t have conditional edges for routing! This is because control flow is defined with Command inside node_a.
Navigate to a node in a parent graph
If you are using subgraphs, you might want to navigate from a node within a subgraph to a different subgraph (i.e. a different node in the parent graph). To do so, you can specifygraph=Command.PARENT in Command:
nodeA in the above example into a single-node graph that we’ll add as a subgraph to our parent graph.
Use inside tools
A common use case is updating graph state from inside a tool. For example, in a customer support application you might want to look up customer information based on their account number or ID in the beginning of the conversation. To update the graph state from the tool, you can returnCommand(update={"my_custom_key": "foo", "messages": [...]}) from the tool:
Command, we recommend using prebuilt ToolNode which automatically handles tools returning Command objects and propagates them to the graph state. If you’re writing a custom node that calls tools, you would need to manually propagate Command objects returned by the tools as the update from the node.
Visualize your graph
Here we demonstrate how to visualize the graphs you create. You can visualize any arbitrary Graph, including StateGraph. Let’s have some fun by drawing fractals :).Mermaid
We can also convert a graph class into Mermaid syntax.PNG
If preferred, we could render the Graph into a.png. Here we could use three options:
- Using Mermaid.ink API (does not require additional packages)
- Using Mermaid + Pyppeteer (requires
pip install pyppeteer) - Using graphviz (which requires
pip install graphviz)
draw_mermaid_png() uses Mermaid.Ink’s API to generate the diagram.
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.